Na crowdsourcingové platformě Crowd Supply byla spuštěna kampaň na podporu open source biometrického monitoru ve tvaru hodinek HealthyPi Move. Cena je 249 dolarů a plánovaný termín dodání listopad letošního roku.
Firma Murena představila /e/OS verze 2.0. Jde o alternativní sestavení Androidu bez aplikací Google. Mezi novinkami je podrobnější nastavení ochrany soukromí před sledováním aplikacemi. Murena prodává několik smartphonů s předinstalovaným /e/OS (Fairphone, repasovaný Google Pixel 5).
Do 30. května lze v rámci akce Warhammer Skulls 2024 získat na Steamu zdarma hru Warhammer 40,000: Gladius - Relics of War.
HelenOS (Wikipedie), tj. svobodný operační systém českého původu založený na architektuře mikrojádra, byl vydán ve verzi 0.14.1. Přehled novinek v poznámkách k vydání. Vypíchnou lze nabídku Start. Videopředstavení na YouTube.
BreadboardOS je firmware pro Raspberry Pi Pico (RP2040) umožňující s tímto MCU komunikovat pomocí řádkového rozhraní (CLI). Využívá FreeRTOS a Microshell.
Vývojáři KDE oznámili vydání balíku aplikací KDE Gear 24.05. Přehled novinek i s náhledy a videi v oficiálním oznámení. Do balíku se dostalo 5 nových aplikací: Audex, Accessibility Inspector, Francis, Kalm a Skladnik.
Byla vydána (𝕏) nová verze 18.0.0 open source webového aplikačního frameworku Angular (Wikipedie). Přehled novinek v příspěvku na blogu.
V neděli 26. května lze navštívit Maker Faire Rychnov nad Kněžnou, festival plný workshopů, interaktivních činností a především nadšených a zvídavých lidí.
Byla vydána nová stabilní verze 3.20.0, tj. první z nové řady 3.20, minimalistické linuxové distribuce zaměřené na bezpečnost Alpine Linux (Wikipedie) postavené na standardní knihovně jazyka C musl libc a BusyBoxu. Z novinek lze vypíchnou počáteční podporu 64bitové architektury RISC-V.
 26.6.2007 21:16
freshmouse | skóre: 42
| blog: Bruno Banány
26.6.2007 21:16
freshmouse | skóre: 42
| blog: Bruno Banány
 26.6.2007 21:52
David Watzke | skóre: 74
| blog: Blog...
| Praha
26.6.2007 21:52
David Watzke | skóre: 74
| blog: Blog...
| Praha

$ time ./schemik -t 0 -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m3.435s user 0m3.191s sys 0m0.047s $ time ./schemik -t 1 -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m3.464s user 0m3.150s sys 0m0.056s $ time ./schemik -t 5 -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m3.589s user 0m3.242s sys 0m0.082sA to se vyplatí
Každopádně seš těžkej šéf, obdivuju tě.
(lambda (n) (+ (fib (- n 1)) (fib (- n 2))) to rozlozi na operace +, (fib (- n 1)) a (fib (- n 2))... aby mohl provest soucet zjisti, ze je potreba pocitat (fib (- n 1)) tak jej zacne pocitat... kdyz planovac zjisti, ze se to pocita nejak dlouho podiva se, jestli by neslo neco vypocitat v novem vlakne... a zjisti ze by mezi tim mohl spocitat (fib (- n 2))... tak to spocita...
cele je to reseno pomoci upraveneho zasobnikoveho modelu od doc. vychodila, palacky university ;-], kterym trapil prvaky. (slibil jsem, ze budu uvadet kredity a odkazy na "nase pracoviste" ;-])
...cast jednovlaknoveho vyhodnocovani je popsana tady, popr. v originalni slidech ...krome toho, ze tento model je strasne jednoduchy a pomaly, jde v nem prave velice snadno delit vypocet do vlaken a ovladat jeho prubeh v case... vcetne krasnych veci jake je call/cc
Although the order of evaluation is otherwise unspecified, the effect of any concurrent evaluation of the operator and operand expressions is constrained to be consistent with some sequential order of evaluation. The order of evaluation may be chosen differently for each procedure call.moje implementace vyhodnocuje vsechny vyrazy z leva doprava, jako rada "prumyslovych" interpretru a prekladacu a snazi se vracet stejne vysledky. ale zastavim se nachvilku u tech side-effectu, protoze s nima je to slozitejsi. jednou z vlastnosti je, ze funkci se side effectem muze provadet hlavni vlakno vypoctu, pokud se objevi nejaky side-effect v pomocnem vlakne je zastaveno (a rozpocitany stav si v budoucnu prebere hlavni vlakno). napr.
(let ((foo (lambda () (display "aaa")))) (foo) (display "bbb") #f)pokud by napriklad pomocne vlakno chtelo vyhodnotit
(display "bbb") ma smulu, protoze nejdriv musi byt vyhodnoceny vsechny vyrazy pred nim.... co kdyby (foo) obsahovalo nejaky dalsi side-effect.
se set! je to jeste slozitejsi.... krome toho, ze ma side-effect, tak nepekne ovlivnuje beh aplikace.
(define global 1) (let () (foo) (set! global 2) (+ global (bar)))pokud by
(foo) a (bar) byly pomale funkce mohl by nastat stav, ze by se treba vyhodnotil vyraz (+ global (bar)) driv nez by se provedlo vyhodnoceni (set! global 2) a diky tomu by se vratil chybny vysledek. tento problem resim tak, ze pokud za operaci typu set! jsou nejaka pomocna vlakna s rozpocitanymi vysledky, tak jsou nemilosrdne zahozena a musi pocitat od znovu -- ano je to plýtvani, ale da se tomu vcelku uspesne branit v planovaci, ktery nepovoli spustit paralelni vypocet za operaci set!
jenom jeste doplnim dva bonbonky, ktere me docela prakvapily -- vstupni funkce napr. (readline) a escape funkce z call/cc maji stejne chovani jako funkce se site-effectem... kdo by to cekal? ;-]
(labels ((a 'a) (b 'b))
(foo
(lambda (print "a: ") (print a))
(lambda (print "b: ") (print b))))
by asi nemělo vypsat a: b b: a.
Což mi přijde při takovéhle implementaci jako problém, protože pokud přidání ladicích výstupů způsobí změnu dělení na streamy, tak si moc nepoladím...
(define (fib-iter a b n)
(if (= n 0) a
(fib-iter b (+ a b) (- n 1))))
(define (fib n)
(fib-iter 0 1 n))
ale tam by se ztratila ta pointa... urcite to potrebuje vetsi intelektualni zatez pro programtora ;-]
 26.6.2007 22:16
andree | skóre: 39
| blog: andreeeeelog
26.6.2007 22:16
andree | skóre: 39
| blog: andreeeeelog

$ time ./schemik -t 0 -s scm/quicksort.scm ./schemik -t 0 -s scm/quicksort.scm 18.74s user 0.04s system 99% cpu 18.948 total $ time ./schemik -t 1 -s scm/quicksort.scm ./schemik -t 1 -s scm/quicksort.scm 17.85s user 0.12s system 144% cpu 12.471 total
$ time ./schemik -t 5 -s scm/quicksort.scm ./schemik -t 5 -s scm/quicksort.scm 19.59s user 0.12s system 136% cpu 14.475 total $ time ./schemik -t 1 -s scm/quicksort.scm ./schemik -t 1 -s scm/quicksort.scm 17.82s user 0.13s system 134% cpu 13.393 total
./schemik -t 5 -s scm/quicksort.scm 19.83s user 0.16s system 138% cpu 14.417 total ./schemik -t 1 -s scm/quicksort.scm 18.06s user 0.12s system 136% cpu 13.313 total ./schemik -t 1 -s scm/quicksort.scm 17.88s user 0.14s system 135% cpu 13.305 total ./schemik -t 5 -s scm/quicksort.scm 19.21s user 0.16s system 142% cpu 13.552 total
(+ (fib (- n 1) (fib (- n 2)) kazde cislo si muze pocitat samostatne vlakno aniz by se nejak ovlivnovali....
tento zpusob vypoctu je fakt hloupy a jde bez problemu prepsat do koncovych volani, kde se budou predavat jiz spocitana cisla.... algoritmus to bude pak velice efektivni... ale neparalelizovatelny....
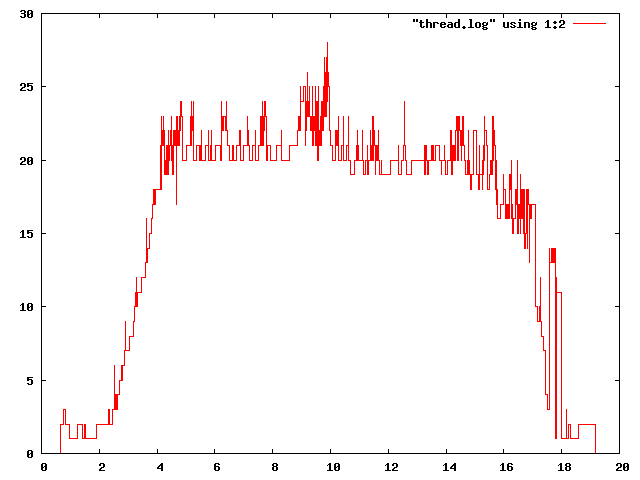
jenom pro zajimavost -- kdyz dam "planovaci" volnou ruku a povolim mu 100 vlaken, aby ukazal jak moc jde uloha paralelizovat, tak u fibonaciho cisla vyuzije skoro vsechny, kdezto u quicksortu ma problemy. (btw paralelizovatelnost ulohy je dana nejen typem algoritmu, ale i vstupnimi hodnotami)
 27.6.2007 12:48
nooneanymore | skóre: 14
| blog: Smazano
27.6.2007 12:48
nooneanymore | skóre: 14
| blog: Smazano
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz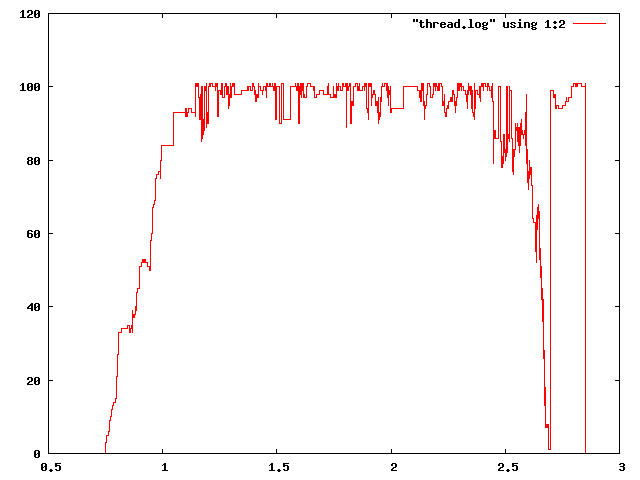{kind=link}
{kind=link}