Byly vyhlášeny výsledky letošní volby vedoucího projektu Debian (DPL, Wikipedie). Staronovým vedoucím zůstává Andreas Tille.
Jason Citron končí jako CEO Discordu. Od pondělí 28. dubna nastupuje nový CEO Humam Sakhnini, bývalý CSO Activision Blizzard.
Článek na Libre Arts představuje baskytarový multiefekt Anagram od společnosti Darkglass Electronics. S Linuxem uvnitř (licence, GitHub).
Městský soud v Praze vyhlásil rozsudek, který vyhověl žalobě novináře Jana Cibulky, který s podporou spolku IuRe (Iuridicum Remedium) požadoval omluvu od státu za to, že česká legislativa nařizuje operátorům uchovávat metadata o elektronické komunikaci. To je přitom v rozporu s právem. Stát se musí novináři omluvit a zaplatit náklady řízení. Především je ale součástí přelomové rozhodnutí o nelegálnosti shromažďování dat a o
… více »Americké technologické firmy Apple a Meta Platforms porušily pravidla na ochranu unijního trhu, uvedla včera Evropská komise (EK). Firmám proto vyměřila pokutu – Applu 500 milionů eur (12,5 miliardy Kč) a Metě 200 milionů eur (pět miliard Kč). Komise to oznámila v tiskové zprávě. Jde o první pokuty, které souvisejí s unijním nařízením o digitálních trzích (DMA). „Evropská komise zjistila, že Apple porušil povinnost vyplývající z nařízení
… více »Americká společnost OpenAI, která stojí za chatovacím robotem ChatGPT, by měla zájem o webový prohlížeč Chrome, pokud by jeho současný majitel, společnost Google, byl donucen ho prodat. Při slyšení u antimonopolního soudu ve Washingtonu to řekl šéf produktové divize ChatGPT Nick Turley.
Po roce vývoje od vydání verze 1.26.0 byla vydána nová stabilní verze 1.28.0 webového serveru a reverzní proxy nginx (Wikipedie). Nová verze přináší řadu novinek. Podrobný přehled v souboru CHANGES-1.28.
Byla vydána nová verze 10.0.0 otevřeného emulátoru procesorů a virtualizačního nástroje QEMU (Wikipedie). Přispělo 211 vývojářů. Provedeno bylo více než 2 800 commitů. Přehled úprav a nových vlastností v seznamu změn.
42 svobodných a otevřených projektů získalo finanční podporu od NLnet Foundation (Wikipedie).
Americký výrobce čipů Intel plánuje propustit více než 20 procent zaměstnanců. Cílem tohoto kroku je zjednodušit organizační strukturu ve firmě, která se potýká s problémy.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
16.2.2019 21:09
| Přečteno: 2186×
| Obecné IT
|  | poslední úprava: 25.2.2019 00:01
| poslední úprava: 25.2.2019 00:01
Ve třetím dílu seriálu Jak se píše programovací jazyk se podíváme na způsob, kterým se z jednorozměrného pole Token objektů udělá syntaktický strom, který pak následně můžeme dále zpracovávat a vyhodnocovat.
Jak bylo popsáno v minulém dílu, Lexer vám kód rozřeže na pole jednotlivých elementů. V mém případě z kódu jako:
(| asd = 1 | ^asd.)
udělá pole ve stylu:
[
Token("OBJ_START", "("),
Token("SEPARATOR", "|"),
Token("IDENTIFIER", "asd"),
Token("ASSIGNMENT", "="),
Token("NUMBER", "1"),
Token("SEPARATOR", "|"),
Token("RETURN", "^"),
Token("IDENTIFIER", "asd"),
Token("OBJ_END", ")")
]
Jde o seznam Token objektů, kde v property .name je uložen název tokenu (například „IDENTIFIER“) a v .value jeho hodnota (například „asd“). Na parseru je poté kód vzít a udělat z něj AST (abstraktní syntaktický strom) ve stylu:
Object(
slots={"asd": Number(1)},
params=[],
parents={},
code=[
Return(
Send(Self(), Message("asd"))
)
],
)
Na to jak je tinySelf jednoduchý jazyk mi dal parser docela zabrat. Původně jsem ho začal psát v RPythonním rpython.rlib.parsing.ebnfparse, což vypadalo opticky dobře a jednoduše:
IGNORE: " |\n";
root: (expression ["\."])* expression;
object: ["("] slots? sends* [")"];
block: ["["] slots? sends* ["]"];
return: ["^"] expression;
expression: IDENTIFIER | value | object | block | send;
#sends: (send ["\."])* send ["\."]?;
sends: (expression ["\."])* expression ["\."]?;
send: (receiver? keyword) | (receiver? message) | (receiver? receiver? operator receiver);
receiver: IDENTIFIER | object | block;
message: IDENTIFIER;
keyword: FIRST_KW_IDENTIFIER >expression< (KEYWORD_IDENTIFIER >expression<)*;
operator: operator_characters+;
operator_characters: "!" | "@" | "#" | "$" | "%" | "&" | "*" | "-" | "+" | \
"=" | "~" | "/" | "?" | "<" | ">" | "," | ";";
slots: ["|"] (>slot_definition< ["\."])* >slot_definition<? ["\."]? ["|"];
slot_definition: IDENTIFIER | (FIRST_KW_IDENTIFIER >expression<) | ARGUMENT;
value: <string> | <float> | <integer>;
float: integer "\." POSINT;
integer: "\-" POSINT | POSINT;
POSINT: "0|[1-9][0-9]*";
ARGUMENT: ":[a-z_][a-zA-Z0-9_\*]*";
IDENTIFIER: "[a-z_][a-zA-Z0-9_\*]*";
FIRST_KW_IDENTIFIER: "[a-z_][a-zA-Z0-9_]*:";
KEYWORD_IDENTIFIER: "[A-Z][a-zA-Z0-9_]*:";
string: SINGLE_QUOTED_STRING | DOUBLE_QUOTED_STRING;
SINGLE_QUOTED_STRING: "'[^\\\']*'";
DOUBLE_QUOTED_STRING: "\\"[^\\\\"]*\\"";
Poměrně záhy jsem však narazil na nedostatek dokumentace a taky na chování, které mi vysloveně vadilo (všechny ty >< a <> kolem identifikátorů, divná rekurze s |, mixování s reguláry atd..). Od začátku jsem to pojal jako TDD development (psatní testů před kódem) a jen díky tomu jsem se z toho nezcvokl, neměl jsem k tomu však daleko.
Bystřejší čtenáři si jistě všimli, že v kódu jsou použity jiné tokeny, než v předchozím díle. Je tomu tak proto, že ebnfparse umožňuje definovat tokeny zároveň s parserem, což rply neumožňuje a to co bylo uvedeno v minulém díle je má pozdější snaha.
Chybějící dokumentace mě časem donutila od RPythonního ebnfparse odejít, speciálně když jsem si procházel ostatní projekty, které používaly jiné parsery. Časem jsem narazil na rply, což je port parseru ply přímo pro RPython. Funguje tak, že píšete dekorátory funkcím ve stylu:
@pg.production('expression : NUMBER')
def expression_number(p):
return Number(int(p[0].getstr()))
Dekorátor určuje pattern z tokenů. Dekorovaná funkce pak co se s tokeny provede. Všechny tokeny jsou předány v poli v proměnné ‚p‘.
V kódu nahoře se vezme první token (index 0) a vratí se objekt Number s tokenem, jehož hodnota byla převedena na číslo.
Number není žádný magický objekt, nadefinoval jsem si ho sám po vzoru ostatních parserů. Dohromady mám tyto objekty, ze kterých se sestavuje syntaktický strom:

Jak je vidět, v tinySelfu existují pouze objekty, bloky, akt poslání zprávy, přeposlání zprávy, kaskáda zpráv (akt poslání několika zpráv jednomu objektu), návrat hodnoty, tři typy zpráv (unární, binární, keyword) a poté čtyři zkratky pro často používané objekty: čísla, stringy, Self a Nil. Self by existovat teoreticky nemusel, mohla by to být jen Message("self") poslaná nikomu, ale zpřehledňuje to kód i výsledný strom. Nil je jen zkratka pro singleton, který by mohl být uložený v globálním namespace.
Zde je ukázka složitějšího transformačního pravidla:
@pg.production('expression : IDENTIFIER')
def unary_message(p):
return Send(obj=Self(), msg=Message(p[0].getstr()))
@pg.production('expression : expression IDENTIFIER')
def unary_message_to_expression(p):
return Send(obj=p[0], msg=Message(p[1].getstr()))
Na ukázce je dobře vidět, jak vzniká poslání zpráv a jak je řešeno vkládání implicitního Selfu. Pokud je identifikátor poslán zdánlivě ničemu, je aktu poslání zprávy předán jako cíl Self(). Pokud je před identifikátorem nějaký výraz, je cíli poslání zprávy předán první token obsahující tento výraz (což už je naparsovaná expression, tedy prvek AST).
Podobnými pravidly je složen celý jazyk. Zde je také hezky vidět rekurzivní povaha parseru, který definuje expression jako identifikátor a poté také jako expression následované identifikátorem. Parser takhle provede rekurzivní pattern matching na všechny odpovídající tokeny, v samotných funkcích se pak jen definuje, co se z toho má složit za AST.
Tenhle přístup má svou výhodu, protože vám dovoluje skládat AST přímo tak jak ho chcete. Předtím používaný ebnf z RPythonu vypadal sice zapsán elegantněji jako jeden krásný string, ale neumožňoval žádné skoro žádné manipupace s AST a vyplivl vám strom z tokenů, který bylo dále třeba zpracovávat. I když to bylo na vyšší úrovni, než samotné pole tokenů, stejně to byl masivní opruz. Oproti tomu přímý přístup k datům v rply vám umožňuje vygenerovat rovnou hotový a upravený AST.
Zde je zdrojový kód celého parseru:
Nikdy dřív jsem nepsal takhle složitý EBNF parser a musím říct, že to pro mě byl docela záhul. Naučit se přemýšlet v rekurzivně skládaných definicích mi dalo zabrat, a to ani nemluvím o tom, že jsem pro Self nenašel žádnou EBNF definici, takže jsem si jí podle manuálu +- skládal sám.
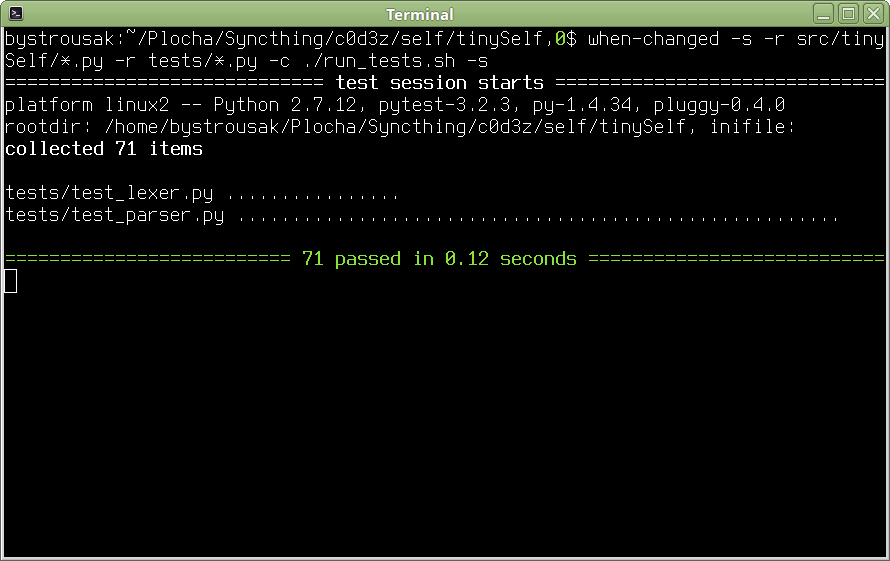
Nakonec se však povedlo a kód prošel všemi testy, které jsem pro něj napsal. Myslel jsem si, že tím to pro mě končí, ale jak se ukázalo, byl to jen začátek další parsovací bolesti, tentokrát spočívající ve snaze kód upravit pro překlad RPythonem.
Příští díl bude takovým mezidílem na téma RPythonu a některých praktických problémů, které jsem musel vyřešit, abych mohl parser a lexer pod ním zkompilovat.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 17.2.2019 16:15
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
17.2.2019 16:15
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 17.2.2019 20:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
17.2.2019 20:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nakonec jsem zplacal programek, ktery prolezl vsechny zdrojaky, zmapoval tridy a vztahy mezi nimi a vygeneroval zadani pro graphviz.Hehe, to jsem před pár lety napsal taky. Tenkrát jsem si zakládal na tom, že mám v dokumentaci vždycky i pár obrázků, ze kterých je možné letmým pohledem pochopit vztahy v kódu, jednak co je tam za struktury, ale taky jak je použít, kde jsem UML znásilňoval tak aby popisovalo tok programu.
Toto ale vypada lepe a srozumitelne - rozhodne vystup je daleko lepsi nez u graphvizu pred lety.Pokud se nepletu, tak plantuml na graphvizu staví, akorát ho v podstatě omezuje na jím používané diagramy. Ale nejsem si tím jistý stoprocentně.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz