Byla vydána (𝕏) květnová aktualizace aneb nová verze 1.90 editoru zdrojových kódů Visual Studio Code (Wikipedie). Přehled novinek i s náhledy a animovanými gify v poznámkách k vydání. Ve verzi 1.90 vyjde také VSCodium, tj. komunitní sestavení Visual Studia Code bez telemetrie a licenčních podmínek Microsoftu.
Byla vydána (Mastodon, 𝕏) nová verze 2024.2 linuxové distribuce navržené pro digitální forenzní analýzu a penetrační testování Kali Linux (Wikipedie). Přehled novinek se seznamem nových nástrojů v oficiálním oznámení.
Počítačová hra Tetris slaví 40 let. Alexej Pažitnov dokončil první hratelnou verzi 6. června 1984. Mezitím vznikla celá řada variant. Například Peklo nebo Nebe. Loni měl premiéru film Tetris.
MicroPython (Wikipedie), tj. implementace Pythonu 3 optimalizovaná pro jednočipové počítače, byl vydán ve verzi 1.23.0. V přehledu novinek je vypíchnuta podpora dynamických USB zařízení nebo nové moduly openamp, tls a vfs.
Canonical vydal Ubuntu Core 24. Představení na YouTube. Nová verze Ubuntu Core vychází z Ubuntu 24.04 LTS a podporována bude 12 let. Ubuntu Core je určeno pro IoT (internet věcí) a vestavěné systémy.
Databáze DuckDB (Wikipedie) dospěla po 6 letech do verze 1.0.0.
Intel na veletrhu Computex 2024 představil (YouTube) mimo jiné procesory Lunar Lake a Xeon 6.
Na blogu Raspberry Pi byl představen Raspberry Pi AI Kit určený vlastníkům Raspberry Pi 5, kteří na něm chtějí experimentovat se světem neuronových sítí, umělé inteligence a strojového učení. Jedná se o spolupráci se společností Hailo. Cena AI Kitu je 70 dolarů.
Byla vydána nová verze 14.1 svobodného unixového operačního systému FreeBSD. Podrobný přehled novinek v poznámkách k vydání.
Společnost Kaspersky vydala svůj bezplatný Virus Removal Tool (KVRT) také pro Linux.

Dneska si jako správné novomediální *** ukážeme, jak jednoduše udělat naprosto zbytečný (ale vypadá to fakt pěkně) word cloud s pomocí programu R project.
Co k tomu potřebujeme:
Jako první si pustíme R konzoli a nainstalujeme potřebné balíčky.
# instalace knihoven
install.packages("Rfacebook")
install.packages("tm")
install.packages("wordcloud")
# nacteni knihoven
library(Rfacebook)
library(tm)
library(wordcloud)
Jakmile si seženeme facebook token, ze stránky https://developers.facebook.com/tools/explorer, můžeme se zvesela pustit do načítání dat z Facebooku pomocí R. Nám bude stačit načíst 300 komentářů z jakékoliv Facebook stránky. A trochu si je předpřipravíme.
# nacteni tokenu do promenne
token <- "token_pro_graph_api"
# nacteni prispevku stranky do promenne
page <- getPage("biooo.cz", token=token, n=300)
# vytvoreni korpusu, ktery bude obsahovat pouze sloupec se zpravami
corpus <- Corpus(VectorSource(page$message))
# slova z korpusu zmenšíme, odstraníme interpunkci a čísla
corpus <- tm_map(corpus, tolower)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
V další fázi vytvoříme z předpřipraveného korpusu matici slov a spočteme jejich frekvenci.
ap.tdm <- TermDocumentMatrix(corpus) ap.m <- as.matrix(ap.tdm) ap.v <- sort(rowSums(ap.m), decreasing=TRUE) ap.d <- data.frame(word = names(ap.v), freq=ap.v)
Již se zdárně blížíme k cíli, teď si načteme do proměnné předpřipravenou paletu barev:
require(RColorBrewer) pal <- brewer.pal(8,"Dark2")
Nyní stačí již jen nastavit soubor výstupu a spustit samotné vytvoření word cloudu!
png("wordcloud.png",width=1024,height=1024)
wordcloud(ap.d$word,ap.d$freq, scale=c(10,.2),min.freq=3,max.words=150, random.order=FALSE, rot.per=.15, colors=pal)
dev.off()
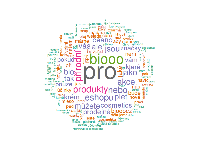
TADÁ! Máme náš první word cloud.
Spousta věcí! Především:
Přece absolutně k ničemu!  P.S. Hlavně to neukazujte markeťákům, nebo vám utrhají ruce!
P.S. Hlavně to neukazujte markeťákům, nebo vám utrhají ruce!
Zdroj: https://gist.github.com/josefslerka/2344144
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 24.11.2013 17:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
24.11.2013 17:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 24.11.2013 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
24.11.2013 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 25.11.2013 09:12
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
25.11.2013 09:12
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz