Byla vydána (𝕏) květnová aktualizace aneb nová verze 1.90 editoru zdrojových kódů Visual Studio Code (Wikipedie). Přehled novinek i s náhledy a animovanými gify v poznámkách k vydání. Ve verzi 1.90 vyjde také VSCodium, tj. komunitní sestavení Visual Studia Code bez telemetrie a licenčních podmínek Microsoftu.
Byla vydána (Mastodon, 𝕏) nová verze 2024.2 linuxové distribuce navržené pro digitální forenzní analýzu a penetrační testování Kali Linux (Wikipedie). Přehled novinek se seznamem nových nástrojů v oficiálním oznámení.
Počítačová hra Tetris slaví 40 let. Alexej Pažitnov dokončil první hratelnou verzi 6. června 1984. Mezitím vznikla celá řada variant. Například Peklo nebo Nebe. Loni měl premiéru film Tetris.
MicroPython (Wikipedie), tj. implementace Pythonu 3 optimalizovaná pro jednočipové počítače, byl vydán ve verzi 1.23.0. V přehledu novinek je vypíchnuta podpora dynamických USB zařízení nebo nové moduly openamp, tls a vfs.
Canonical vydal Ubuntu Core 24. Představení na YouTube. Nová verze Ubuntu Core vychází z Ubuntu 24.04 LTS a podporována bude 12 let. Ubuntu Core je určeno pro IoT (internet věcí) a vestavěné systémy.
Databáze DuckDB (Wikipedie) dospěla po 6 letech do verze 1.0.0.
Intel na veletrhu Computex 2024 představil (YouTube) mimo jiné procesory Lunar Lake a Xeon 6.
Na blogu Raspberry Pi byl představen Raspberry Pi AI Kit určený vlastníkům Raspberry Pi 5, kteří na něm chtějí experimentovat se světem neuronových sítí, umělé inteligence a strojového učení. Jedná se o spolupráci se společností Hailo. Cena AI Kitu je 70 dolarů.
Byla vydána nová verze 14.1 svobodného unixového operačního systému FreeBSD. Podrobný přehled novinek v poznámkách k vydání.
Společnost Kaspersky vydala svůj bezplatný Virus Removal Tool (KVRT) také pro Linux.
Je aplikace primárně určená pro správu filmových sbírek. Ale zjistil jsem, že je docela dobře využitelná i pro správu souborů elektronických knih. Přišel jsem na to víceméně náhodou, když se do seznamu souborů z vybrané lokace natáhly i soubory, které nebyly zrovna multimediální.
Už řadu let syslím data. Jsou to data různá. Obrázky, elektronické knihy, audio knihy, filmy, hudba… Dohnala mne k tomu pomíjivost internetových zdrojů. Nechápete? Stačí se podívat na wikipedii, která je plná neplatných odkazů na internetové články, které skončily v propadlišti dějin. Visí tam, protože jimi svého času někdo podložil sdělení uvedené v obsahu.
Většině konzumentů je to nejspíš ukradené, ale několikrát se mi stalo, že webová stránka, ze které jsem načerpal nějakou informaci zmizela. Proto jsem si začal místo URL adres syslit pro případné budoucí použití konkrétní obsah.
Pokud jde o webové stránky, tak používám už přes dvacet let operu, která umí uložit obsah stránky (včetně obrázků) do jednoho mht souboru. Poměrně jednoduché je to i s obrázky. Tam s výhodou využívám toho, že geeqie umí vložit poznámku rovnou do souboru. Obvykle tak do ukořistěného obrázku ukládám kromě popisu také URL ze kterého obrázek pochází.
Větší problém pro mne představovaly elektronické knihy. Přejmenovat soubor podle názvu knihy, nebo mu ponechat originální název a pak nějakým způsobem vytahovat název knihy z metadat přes exif? Těžko říct. Můj kamarád, uživatel MS Windows je sysel, co využívá pro ukládání dat podadresářovou strukturu. Ovšem, jak chcete roztřídit soubory, které nelze jednoznačně zařadit a vyhnout se při tom duplicitě?
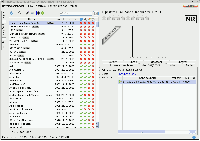
Zkoušel jsem různé aplikace a nakonec se ukázalo, že mi nejvíc vyhovuje tinyMediaManager, i když je primárně určen pro filmy. Stačí přidat přípony požadovaných souborů (djvu, pdf, aj.) a pak mu předhodit adresář ve kterém jsou ty digitalizované knihy naházené.
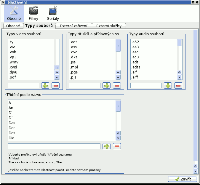
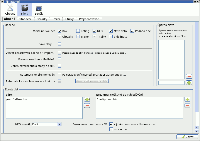
Po aktualizaci rozšíří seznam souborů o nově přidané položky, které pak lze dle libosti popsat a oštítkovat. Chci-li pak nějakou knihu otevřít, stačí v záložce "Soubory médií" kliknout na soubor. Ostatní informace o původu souboru, stručné shrnutí obsahu a případně i náhled titulní stránky lze přidat stejně jako u každého jiného multimediálního souboru.
Vyhovuje mi, že tak mohu prostřednictvím jedné aplikace spravovat jak multimediální soubory tak i digitalizované dokumenty. A pomocí filtru podle potřeby rychle vylistovat co mne zrovna zajímá.
To, že jsou všechny dokumenty naházené do jednoho adresáře má zas výhodu v tom, že se mi snáz vyhledává fulltextově.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 4.12.2018 11:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
4.12.2018 11:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Proto jsem si začal místo URL adres syslit pro případné budoucí použití konkrétní obsah.Přijde mi mnohem lepší to manuálně strkat do webarchivu. Používám na to následující bookmarklet:
javascript:location.href='http://web.archive.org/save/'+location.href
 6.12.2018 23:45
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
6.12.2018 23:45
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz