Jakub Jelínek oznámil vydání verze 15.1 (15.1.0) kolekce kompilátorů pro různé programovací jazyky GCC (GNU Compiler Collection). Jedná se o první stabilní verzi řady 15. Přehled změn, nových vlastností a oprav a aktualizovaná dokumentace na stránkách projektu. Některé zdrojové kódy, které bylo možné přeložit s předchozími verzemi GCC, bude nutné upravit.
Byly vyhlášeny výsledky letošní volby vedoucího projektu Debian (DPL, Wikipedie). Staronovým vedoucím zůstává Andreas Tille.
Jason Citron končí jako CEO Discordu. Od pondělí 28. dubna nastupuje nový CEO Humam Sakhnini, bývalý CSO Activision Blizzard.
Článek na Libre Arts představuje baskytarový multiefekt Anagram od společnosti Darkglass Electronics. S Linuxem uvnitř (licence, GitHub).
Městský soud v Praze vyhlásil rozsudek, který vyhověl žalobě novináře Jana Cibulky, který s podporou spolku IuRe (Iuridicum Remedium) požadoval omluvu od státu za to, že česká legislativa nařizuje operátorům uchovávat metadata o elektronické komunikaci. To je přitom v rozporu s právem. Stát se musí novináři omluvit a zaplatit náklady řízení. Především je ale součástí přelomové rozhodnutí o nelegálnosti shromažďování dat a o
… více »Americké technologické firmy Apple a Meta Platforms porušily pravidla na ochranu unijního trhu, uvedla včera Evropská komise (EK). Firmám proto vyměřila pokutu – Applu 500 milionů eur (12,5 miliardy Kč) a Metě 200 milionů eur (pět miliard Kč). Komise to oznámila v tiskové zprávě. Jde o první pokuty, které souvisejí s unijním nařízením o digitálních trzích (DMA). „Evropská komise zjistila, že Apple porušil povinnost vyplývající z nařízení
… více »Americká společnost OpenAI, která stojí za chatovacím robotem ChatGPT, by měla zájem o webový prohlížeč Chrome, pokud by jeho současný majitel, společnost Google, byl donucen ho prodat. Při slyšení u antimonopolního soudu ve Washingtonu to řekl šéf produktové divize ChatGPT Nick Turley.
Po roce vývoje od vydání verze 1.26.0 byla vydána nová stabilní verze 1.28.0 webového serveru a reverzní proxy nginx (Wikipedie). Nová verze přináší řadu novinek. Podrobný přehled v souboru CHANGES-1.28.
Byla vydána nová verze 10.0.0 otevřeného emulátoru procesorů a virtualizačního nástroje QEMU (Wikipedie). Přispělo 211 vývojářů. Provedeno bylo více než 2 800 commitů. Přehled úprav a nových vlastností v seznamu změn.
42 svobodných a otevřených projektů získalo finanční podporu od NLnet Foundation (Wikipedie).
Poznámka redakce: Tento text je odvozen ze školní práce, vychází se svolením autora. Formátování bylo upraveno pro podmínky webu.
Práce se zabývá současným stavem implementace sémantického desktopu v operačním systému GNU/Linux. Nejprve práce shrnuje výzkumný projekt NEPOMUK, který položil základy pro sociální sémantický desktop. Poté práce uvádí ontologie, na kterých sémantický desktop staví. Následně jednu z nich podrobněji ukazuje.
Pak se práce zabývá projektem NEPOMUK-KDE, tedy implementací sociálního sémantického desktopu do linuxového prostředí KDE 4. Práce poskytuje základní pohled na architekturu Nepomuku v KDE a způsob, jakým zaznamenává metadata. Následně práce shrnuje nedávný vývoj projektu a ukazuje oblasti, na kterých se pracuje nyní.
Závěrečná část práce se snaží poskytnout uživatelský pohled na současný stav sociálního sémantického desktopu v KDE 4. Práce ukazuje jednotlivé možnosti využití Nepomuku, tj. vyhledávání a anotování ve správci souborů Dolphin, spouštěči programů KRunner, prohlížeči obrázků Gwenview a přehrávači médií Bangarang.
Projekt NEPOMUK probíhal od počátku roku 2006 do konce roku 2008 za finanční účasti Evropské Unie. Hlavním cílem tohoto projektu bylo poskytnout infrastrukturu rozšiřující osobní desktop do prostředí podporujícího jak správu osobních informací, tak i sdílení a výměnu těchto informací v rámci sociálních a organizačních vztahů. Projekt tedy definuje sociální sémantický desktop. Technologie a metodiky stojí na přiřazování i generování metadat, propojování aplikací i médií na základě standardů sémantického webu, sdílení znalostí v sociálních sítích a distribuovaném hledání a ukládání informací a vztahů v rámci pracovního prostředí. Výsledný framework staví na open source vývoji a oficiální standardizaci vzniklých rozhraní a struktur. Kromě referenční implementace nastartoval tento projekt vývoj OSS implementace sociálního sémantického desktopu integrovaného do KDE (NEPOMUK – KDE) a také komerční implementace GNOWSIS – CLUUG. Viz [1, 2].
Pro reprezentaci dat uživatelského informačního prostředí používá NEPOMUK RDF. Samotné RDF je ale značně nízkoúrovňová technologie. Pro reprezentaci vysokoúrovňových znalostí sémantického desktopu se tedy využívají konstrukty vyšších jazyků RDFS a OWL a také vlastní jazyk pro práci s pojmenovanými grafy NRL. Tyto jazyky umožňují dohromady vytvářet ontologie potřebné pro výměnu dat a integraci aplikací na distribuovaných sociálních sémantických desktopech. Vytvořené ontologie jsou spravovány a standardizovány v rámci OSCA Foundation. Současné verze ontologií udržované OSCA Foundation vznikly spojením původních ontologií projektu NEPOMUK s ontologií projektu Xesam zastřešeného freedesktop.org. Kromě KDE využívá tyto ontologie i Strigi a Tracker. Viz [3, 7, 14].
Ontologie udržované OSCA Foundation zahrnují anotační ontologii NAO, skupinu ontologií pro informační elementy NIE, ontologii pro modelování osobních informací PIMO a ontologii pro modelování úkolů TMO. Ontologie NAO se používá především pro popis a anotaci pojmenovaných grafů vytvořených v NRL. Skupina ontologií NIE poskytuje prostředky pro modelování informací, které jsou běžně součástí sémantického desktopu, tj. metadata o souborech, zprávách a e-mailech, kontaktech, záznamech v kalendářích a pro informace uložené v EXIF či ID3. PIMO ontologie je určená k integraci údajů o osobách a jiných subjektech reálného světa poskytovaných ostatními ontologiemi. Viz [3, 7, 8].
NFO je součástí skupiny ontologií NIE. Slouží k zachycení informací získaných ze zdrojů, jako jsou lokální či síťové soubory. Základním stavebním kamenem této ontologie je třída FileDataObject, která reprezentuje soubory včetně webových dokumentů dostupných přes URL. Různé typy souborů zachycuje rozšiřitelná taxonomie podtříd třídy File. Adresáře či složky, ale také komprimované adresáře či adresáře IMAP serveru reprezentuje třída Folder. Nepomuk usiluje o integraci dat, a proto při přiřazování vztahem belongsToContainer nerozlišuje, zda jde o adresář, složku archivu či mailboxu, používá se prostě třída Folder. Archivy pak zachycuje třída Archive. Pro určení jednotlivých zdrojů používá NFO vlastnost fileURL – URL pak může být umístěné na lokálním či vzdáleném počítači. Pro zachycení sémantiky souboru na vzdáleném počítači slouží třída RemoteDataObject. Viz [4].
Projekt NEPOMUK-KDE je komunitní OSS projekt, jehož cílem je implementovat standardy a API projektu NEPOMUK do linuxového desktopového prostředí KDE. Stejně jako NEPOMUK se i NEPOMUK-KDE zaměřuje na správu a využití metadat v rámci pracovního prostředí a nástrojů pro peer-to-peer spolupráci. Dosavadní vývoj se soustředí především na zpracování a využití metadat. Jde o metadata, která se už nyní nachází v souborech na disku, tj. tagy v audio souborech či obrázcích či indexované texty. K jejich získání se používá vyhledávání realizované pomocí Strigi. Další metadata může přidat uživatel ručně pomocí tagů k libovolným souborům. A konečně jde o metadata odvoditelná z kontextu jako například, ze kterého URL byl soubor stažen, nebo ke kterému e-mailu byl soubor před uložením přiložen. Viz [5].
NEPOMUK-KDE je realizován Nepomuk serverem a klientskými aplikacemi, které k němu přistupují pomocí knihoven Nepomuk frameworku, jak ukazuje obrázek 1. Nepomuk server je tvořen jednotlivými službami, které se starají o správu ontologií, sledování změn souborů, odpovídání dotazů, integraci Strigi a konečně o úložiště RDF. Jako úložiště RDF se používá Soprano. Soprano samo o sobě je opět framework, který může mít různé backendy, jež teprve řeší vlastní ukládání dat. Současně používaný backend je Virtuoso, který ukládá RDF do SQL databáze. Celá architektura je značně modulární a lze využívat výhod klient-serverové koncepce (např. Virtuoso server může být na vzdáleném počítači). Jednotlivé komponenty využívají ke vzájemné komunikaci DBus. Viz [9, 11, 12, 13].
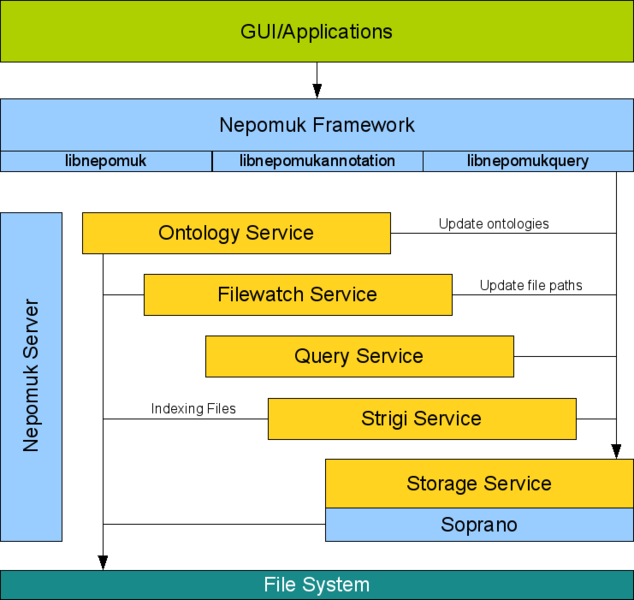
Nepomuk server pracuje především se získanými metadaty o souborech. Z hlediska Nepomuku jde o data. K nim si Nepomuk vytváří vlastní metadata. Zpracovávaná data a metadata pocházejí z různých zdrojů. Automaticky získaná data ukládá Strigi s využitím NIE ontologií. Pro každý soubor zpracovaný Strigi se vytváří dva pojmenované grafy v jazyce NRL. První graf obsahuje všechna extrahovaná metadata o souboru jako velikost, URL, zaindexovaný text, MIME typ, datum poslední změny souboru a další. Druhý pojmenovaný graf obsahuje metadata o prvním grafu: Konkrétně jde o datum, kdy byl graf indexován Strigi, a URI grafu. Toto rozdělení usnadňuje aktualizaci metadat získaných Strigi – zastaralý graf se prostě odstraní a nahradí novým. Obdobné rozvržení se využívá pro ukládání metadat, kterými uživatel anotuje soubory v koncové aplikaci. Jeden pojmenovaný graf obsahuje vlastní metadata o souboru – tedy tagy přiřazené uživatelem – zatímco druhý graf obsahuje metadata o těchto metadatech – tj. datum vytvoření anotace a URI grafu s anotací. A konečně Nepomuk ukládá stejným způsobem i samotné ontologie. Jeden pojmenovaný graf obsahuje definice tříd a vlastností, druhý pak metadata o ontologii, jako jsou jména autorů, číslo verze, datum poslední změny a podobně. Viz [8].
Současná verze KDE SC 4.4 přinesla nový backend pro Soprano – Virtuoso. Mezi jeho výhody patří nižší spotřeba systémových prostředků oproti dříve používaným backendům, lepší podpora dotazovacího jazyka SPARQL a vyšší výkon při zpracování dotazů. Změna backendu umožnila také konečně specifikovat dotazovací API, které lze využívat při tvorbě KDE aplikací – první implementace se API dočkalo ve vyhledávacím rozhraní správce souborů Dolphinu. Postupně přibývají aplikace, které Nepomuk dokáží využívat, jako například přehrávač médií Bangarang. Viz [14].
Připravovaná verze KDE SC 4.5 by měla dále zlepšit integraci Nepomuku s KDE. Integrace s Nepomukem by se měl dočkat prohlížeč Konqueror – Nepomuk bude řešit záložky. Nepomuk by měl také zlepšit řazení výsledků vyhledávání v KRunneru. Nepomuk si bude pamatovat stažené soubory. Jednou z novinek pro Dolphin – která by měla být zařazena – je také fasetové procházení souborů založené na Nepomuku. Další vývoj spojený s Nepomukem probíhá v rámci Google Summer of Code. Pro rok 2010 jsou přihlášeny projekty zabývající se zálohováním a synchronizací metadat Nepomuku, extraktor metadat pro Nepomuk z webu, GUI pro pokročilé hledání pomocí Nepomuku a analyzátor souborů pro Strigi založený na gramatikách pro popis struktury dat. Viz [14, 15, 16].
Velká část dosavadního vývoje Nepomuku pro KDE se soustředila na poskytnutí infrastruktury pro koncové aplikace. Tento vývoj je z pohledu uživatele viditelný především výkonnostním dopadem standardně běžících služeb Nepomuku a zejména indexovače Strigi.
Pro uživatele je dostupná integrace Nepomuku se správcem souborů Dolphin – jde o anotování a vyhledávání – a pak funguje vyhledávání souborů založené na Nepomuku Strigi. Se Strigi jsou spojené další aplikace – již zmiňované vyhledávací políčko v Dolphinu a zásuvný modul do spouštěče aplikací KRunneru. Poměrně dlouho je také dostupná podpora pro anotování a hodnocení využívající Nepomuk v prohlížeči obrázků Gwenview. Viz [6, 17].
Následuje popis podpory Nepomuku ve vybraných programech KDE. Testy probíhaly na distribuci Arch Linux s KDE SC 4.4.3, systém je udržován plně aktualizovaný. Služby Nepomuku a Strigi byly spuštěny s výchozí konfigurací až při zahájení testování – uživatelský dojem by tedy neměl být ovlivněn pozůstatky dřívějších problémů.
Integrace Nepomuku a Dolphinu zahrnuje zobrazení sémantických informací o souborech a složkách, možnost ruční anotace a konečně sémantické vyhledávání.
Pravý panel Dolphinu obsahuje informace o vybraných souborech či složkách. Mimo jiné zobrazuje také vybraná metadata, ať už zaindexovaná pomocí Strigi, nebo přidaná uživatelem. Jak je vidět na obrázku 2, vyrovnává se Dolphin s různými soubory různě dokonale. O PDF dokumentu či videu AVI nezobrazuje žádná jiná než základní metadata – u videa to není překvapivé, ale u PDF dokumentu jde o zklamání. Například zobrazení určitého počtu nejčetnějších klíčových slov, by podle autora práce bylo přínosné. O textovém souboru vytvořeném nástrojem diff zobrazuje Dolphin mnoho metadat statistického typu. Pro zvukový soubor ve formátu FLAC zobrazuje Dolphin metadata obsažená v ID3 tagu. O fotografii v JPG zobrazuje metadata z EXIF tagu a základní metadata jako například rozměry. O adresáři Dolphin zobrazuje pouze základní sémantické informace – které jsou dostupné i pro ostatní soubory – a sice hodnocení, značky, komentář a nadřazený objekt asociovaný vztahem isPartOf.
Možnosti ruční anotace souborů a složek spočívají v přidání značek (tagů), textového komentáře a hodnocení na škále 0–10. Vše se provádí v pravém panelu Dolphinu kliknutím na příslušný odkaz či daný počet hvězdiček v případě hodnocení. Okno s přidáním značek nabízí jak výběr z dosud použitých značek, tak i možnost vytvořit značku novou.
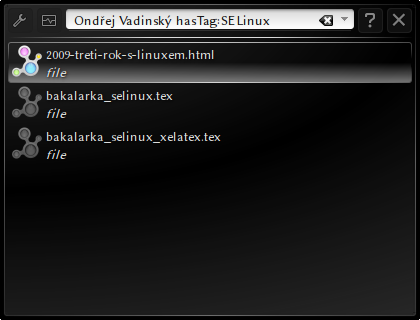
Uživatelské rozhraní Dolphinu obsahuje vyhledávací políčko. Pokud do něj uživatel umístí kurzor, objeví se panel s filtry hledání. Výchozí filtr hledá všechny typy souborů zaindexované kdekoliv v počítači. Lze ale specifikovat, zda se mají hledat jen obrázky, text, nebo jen názvy souborů a dále, zda se má hledat v aktuálním adresáři a jeho podstromu. Kliknutím na tlačítko s ikonou plus může uživatel přidat pokročilé filtry, a sice podle data, velikosti, značek a hodnocení. Možnosti filtrování podle data obsahují jak předpřipravené varianty jako Dnes, Tento týden, tak i varianty výběru intervalu. U velikosti souborů lze vytvářet intervaly, do kterých má tato velikost spadat. U filtru podle značky je dostupný seznam použitých značek, není ale možné negativní vymezení. Filtr hodnocení je realizován určením typu intervalu a výběrem žádaného počtu hvězdiček. Filtry lze snadno kombinovat do silných dotazů. Filtry lze také zadat ručně pomocí parametrů: contentSize, lastModified, tag, title, fileExtension, … Samotný text dotazu lze spojovat logickými operátory. Během zadávání dotazu napovídá Dolphin názvy tagů, parametrů a operátorů. Příklad vyhledávání s několika filtry ukazuje obrázek 3.

Bez běžícího Nepomuk serveru zobrazuje Dolphin pouze informace o typu souboru, jeho velikost a čas poslední změny, anotační funkce je samozřejmě vypnutá.
Integrace Nepomuku a KRunneru je řešena pomocí zásuvného modulu. Pak je možné obdobné vyhledávání jako v Dolphinu, přičemž dotazy lze upřesňovat výše zmíněnými parametry. Obdobný dotaz jako na obrázku 3 zachycuje obrázek 4. Síla takto realizovaného vyhledávání spočívá v jeho pohotovosti a kombinaci s výsledky dalších vyhledávacích modulů KRunneru. Slabinou je zadávání složitějších dotazů, i když zde značně záleží na preferencích uživatele.
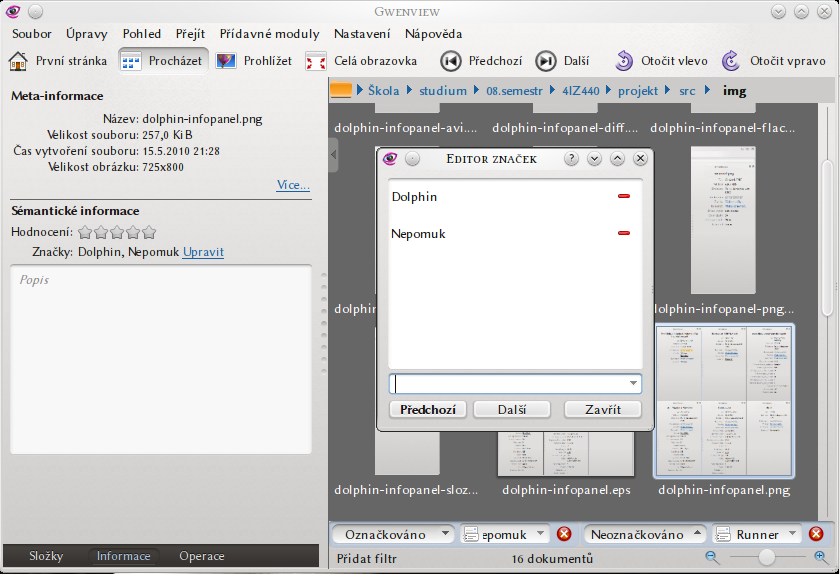
Integrace Nepomuku a Gwenview umožňuje zobrazení některých sémantických metadat, ruční anotaci souborů, filtrování a vyhledávání. Sémantická metadata zobrazuje Gwenview v kartě informace bočního panelu. Opět jde o přiřazené značky, hodnocení a textový komentář. Tato metadata lze také měnit ruční anotací. Při prohlížení obrázků v adresáři lze aplikovat filtry, mimo jiné podle značek. Zobrazená metadata, jejich změnu a filtrování zachycuje obrázek 5. Úvodní stránka aplikace zobrazuje seznam použitých značek Nepomuku. Kliknutí na některou značku vyvolá hledání všech obrázků s danou značkou. Bez běžícího Nepomuku dokáže Gwenview stále zobrazit informace z EXIF tagů souborů – ač jsou tedy tato metadata indexována pomocí Strigi a uložena v Nepomuku, Gwenview k nim přistupuje přímo.
Integrace Nepomuku s Bangarangem umožňuje tomuto přehrávači vytvářet knihovnu médií. Při tom přidá Bangarang do Nepomuku mnoho metadat o zdrojích, jak ukazuje níže následující výpis o zdroji poskytnutý přes KIO slave nepomuk:/. Úvodní interakce s Nepomukem zabere Bangarangu nějaký čas v závislosti na rozsáhlosti hudební kolekce. Následující práce s kolekcí probíhají téměř okamžitě.
Generace Type: Resource Vztahy: created at Dnes 10:34 title Generace last modified at Dnes 10:34 identifier music-album-Generace Zpětné odkazy: Amerika (file, music, MusicPiece) musicAlbum Když pohlédnu na dítě (file, music, MusicPiece) musicAlbum Věřím (file, music, MusicPiece) musicAlbum Spartakiáda (file, music, MusicPiece) musicAlbum Televize (file, music, MusicPiece) musicAlbum Gud džouk (file, music, MusicPiece) musicAlbum Generace (file, music, MusicPiece) musicAlbum Sprostá (file, music, MusicPiece) musicAlbum Ke tricatemu vyroci (file, music, MusicPiece) musicAlbum Chua Huo – seng (file, music, MusicPiece) musicAlbum Vojna (file, music, MusicPiece) musicAlbum Sádlo (file, music, MusicPiece) musicAlbum Indie (file, music, MusicPiece) musicAlbum Šílenství (file, music, MusicPiece) musicAlbum Rádio (file, music, MusicPiece) musicAlbum Pivo (file, music, MusicPiece) musicAlbum Ach synku, synku (file, music, MusicPiece) musicAlbum Kreatura (file, music, MusicPiece) musicAlbum Pracovní tábor (file, music, MusicPiece) musicAlbum Život je jen náhoda (file, music, MusicPiece) musicAlbum Leningrad (file, music, MusicPiece) musicAlbum Kain (file, music, MusicPiece) musicAlbum Betlém (file, music, MusicPiece) musicAlbum Půjčka (file, music, MusicPiece) musicAlbum Vstavej lasko ma (file, music, MusicPiece) musicAlbum Rána morová (file, music, MusicPiece) musicAlbum
Tato metadata zobrazuje nyní také Dolphin – zde se začíná ukazovat síla sémantického desktopu. Knihovna médií Bangarangu odpovídá knihovnám médií dalších přehrávačů. Zobrazuje umělce, alba, skladby, žánry, …poskytnuté Nepomukem. Na úrovni jednotlivých stop lze tato metadata zobrazit a editovat – vybraná metadata se také zobrazují při přehrávání stop. V knihovně médií lze také vyhledávat. Zobrazení metadat ukazuje obrázek 6.
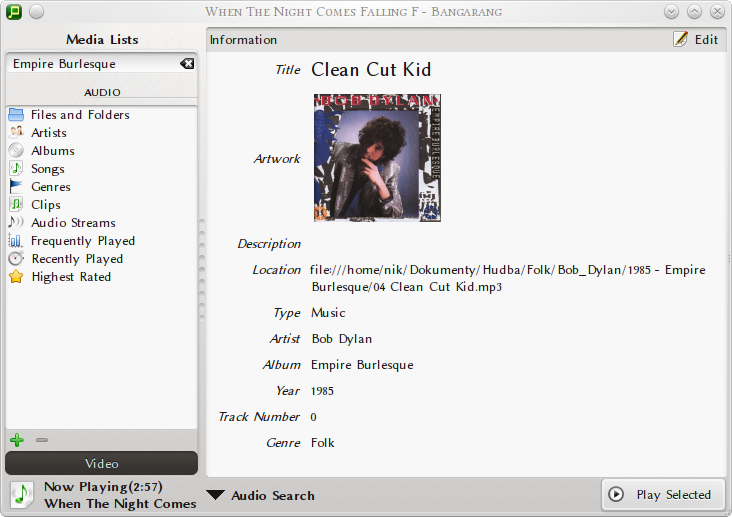
Nepomuk rozšiřuje také nabídku dostupných KDE KIO slaves. Konkrétně jsou to tyto KIO slaves: nepomuk:/, nepomuksearch:/ a timeline:/. Ty lze využívat buď přes nějakou aplikaci – jako je například vyhledávací políčko v Dolphinu, nebo přímo – zadáním příslušného názvu včetně jeho případných parametrů do adresního řádku Konqueroru nebo zmiňovaného Dolphinu.
KIO nepomuk:/ umožňuje mimo jiné zobrazit informace o zdrojích, které Nepomuk vede, na základě jejich identifikátoru, viz výpis v předchozí sekci, který vznikl zadáním nepomuk:/res/24e9e7f8-1d25-4000-aa71-586ceb56ec5f do příkazového řádku Konqueroru.
KIO nepomuksearch:/ provádí dotazy nad úložištěm Nepomuku. Zadat lze buď jednoduché dotazy obdobně jako ve vyhledávacím políčku Dolphinu nebo lze využít jazyk SPARQL. Syntaxi dotazů se věnuje zdroj [9].
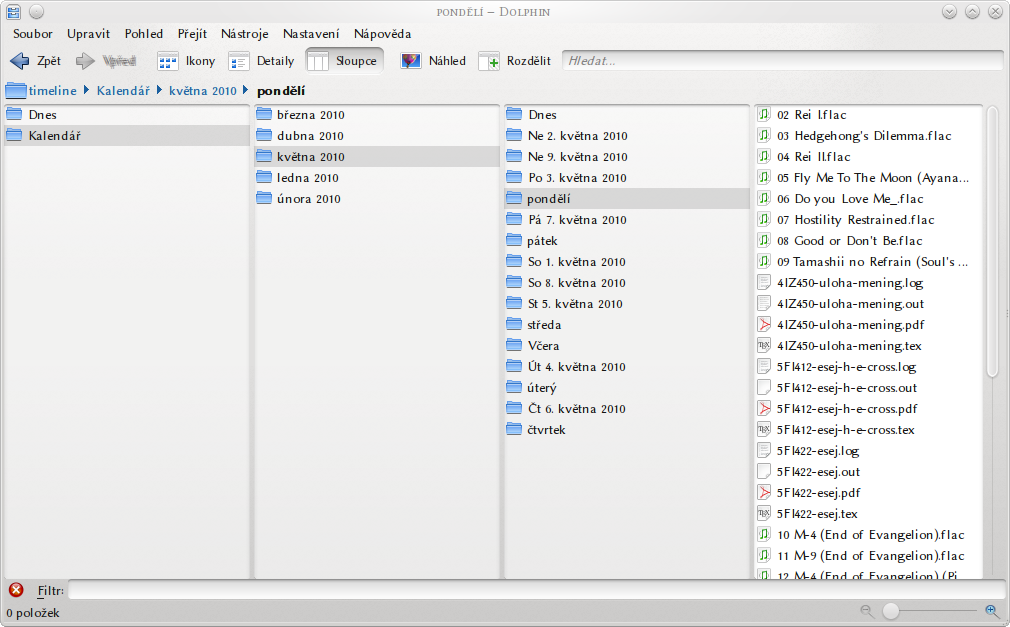
KIO timeline:/ využívá Nepomuk ke zjištění data posledního přístupu k souborům. Uživateli nabízí kalendářový pohled na jeho soubory organizované do složek, které odpovídají jednotlivým dnům. Kliknutí na některou složku vyvolá příslušný dotaz na Nepomuk, jehož výsledky vrátí KIO slave uživateli. Fungování KIO timeline:/ ukazuje obrázek 7.
Práce poskytla úvod do problematiky tzv. sociálního sémantického desktopu zastoupeného v Linuxu projektem NEPOMUK-KDE. V rámci tohoto úvodu ukázala práce základy sémantického desktopu, tj. výzkumný projekt NEPOMUK a ontologie, které v rámci něj vznikly. Dále práce prezentovala technické řešení vzešlé z projektu NEPOMUK-KDE, tedy Nepomuk framework, a ukázala oblasti současného vývoje projektu.
Následně se práce zaměřila na NEPOMUK-KDE z hlediska uživatele, tedy na míru podpory Nepomuk frameworku v KDE aplikacích. Tu ukázala na aplikacích, se kterými koncový uživatel běžné přichází do styku, tedy správci souborů Dolphin, spouštěči aplikací KRunner, prohlížeči obrázků Gwenview a přehrávači médií Bangarang. Integrace Nepomuku do těchto aplikací většinou spočívá v sémantickém vyhledávání, sémantickém anotování uživatelem a prezentaci sémantických informací.
Sémantické vyhledávání funguje dobře a možnosti specifikace jeho dotazů jsou poměrně značné. Zatím však chybí uživatelsky přívětivé GUI pro pokročilé vyhledávání – jeho vývoj je však součástí letošního Google Summer of Code, v KDE ho lze očekávat nejdříve v zimním vydání 4.6.
Prezentace sémantických informací v KDE aplikacích funguje způsobem klíčové slovo – hodnota, která může být odkazem na zdroj. Množství zobrazovaných informací závisí na typu souboru, kterého se týkají. Zklamáním je nezobrazování sémantických informací o PDF souborech. Z výsledků vyhledávání se navíc zdá, že je nějaký problém s indexací těchto dokumentů klíčovými slovy obsahujícími znaky s diakritikou. Chybí také pokročilejší reprezentace vztahů mezi zdroji, např. formou vizualizace grafu zdrojů a vztahů.
Sémantické anotování umožňuje uživateli přidat souborům značky, komentář a hodnocení. V této oblasti vede Bangarang, který umožňuje měnit i jiná sémantická metadata např. název skladby, autora, žánr a podobně. Kromě Bangarangu však zatím není pokročilejší anotování v aplikacích možné.
Zkoušené aplikace nejevily známky nefunkčnosti a během testování byly stabilní, až na KRunner, který s aktivním pluginem pro Nepomuk ojediněle padá.
Kromě koncových aplikací nastínila práce také využití KDE KIO slaves závisejících na Nepomuku. Pokročilý uživatel je může využít k získání informací o zdrojích či jednoduchému i pokročilému vyhledávání. KIO timeline:/ dává uživateli pohled na jeho soubory podle data poslední změny.
Celkově lze říct, že je implementace Nepomuku do KDE aplikací na dobré cestě, ač je stále v počátcích. Zbývá mnoho běžných aplikací, které Nepomuk zatím vůbec nepoužívají. Stejně tak výhody sémantického desktopu se začínají projevovat poměrně pomalu. To ale není příliš překvapivé vzhledem k tomu, že vývoj se před verzí KDE SC 4.4 soustředil především na vlastní framework, bez kterého není možné vyvíjet samotné aplikace. Dá se ale čekat, že aplikací využívajících Nepomuk bude i nadále přibývat.
Provoz Nepomuku s sebou nese zvýšené nároky na systémové zdroje, což může být v některých případech problém. Autor však na svém postarším hardwaru nezaznamenal nic dramatického. Dá se tedy říct, že Nepomuk během svého dosavadního vývoje značně vyspěl a ve většině případů není moc oprávněných důvodů pro jeho vypnutí. Obavy uživatelů pramení zřejmě ze zkušeností se staršími verzemi.
Toto dílo je licencováno pod licencí Creative Commons Uveďte autora – Neužívejte dílo komerčně – Nezasahujte do díla 3.0 Česká republika. Pro zobrazení kopie této licence navštivte http://creativecommons.org/licenses/by-nc-nd/3.0/cz/ nebo pošlete dopis na adresu: Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
use caseJo, tak ty nejsou. Zato jsou "ontologie" (ať už je to co chce). A hezké weby všech těch nadací. Sice bez obsahu, ale zato proseté logy velkých firem které asi nevědí co s prachama. Skoro učebnicový příklad vaporware.
Čo to je ten sociálny sémantický desktop a čo je "ontologie" (to sa radšej nepokúsim napísať v Slovenčine).
To přece není vůbec důležité, co to je. Hlavní je, že je to cool a in a kdo to nemá, je skoro tak out jako když nepoužívá "sociální sítě" nebo "web 2.0" (no, ten už vlastně ne, ten už je out). :-)
Na druhou stranu, dokud půjdou Nepomuk a Strigi vypnout, tak ať si hrají.
 22.6.2010 07:08
Petr Bravenec | skóre: 43
| blog: Bravenec
22.6.2010 07:08
Petr Bravenec | skóre: 43
| blog: Bravenec
 22.6.2010 09:41
Rezza | skóre: 25
| blog: rezza
| Brno
22.6.2010 09:41
Rezza | skóre: 25
| blog: rezza
| Brno
 )
)

Problém existuje dávno - klasifikace a vyhledávání dokumentů - jen ho asi hodně čtenářů abc nemá, záleží na co počítač primárně používáte, on se stane problémem až od určitého množství dokumentů.I středně velká firma produkující ročně několik tisíc dokumentů si obvykle vystačí s rozumnou adresářovou strukturou a archivem. Takže nechápu, jak by někdy mohl dospět desktop jednoho uživatele do bodu kde není schopen najít co potřebuje během dvou-tří úkonů. Navíc se nezdá, že by nepomuk sedící v ~/.kde oplýval nějakými schopnostmi se sdílet třeba s jinými uživateli ve firmě.
Protože, tu databázy musíte nějak vytvořit, zaplnit, aktualizovat, navrhnout rozumnou strukturu vyhovující záměru.Zdá se, že to je propagace stylu "one size fits all".
A tohle všechno mimo jiné řeší Nepomuk.Ale jak? Nikdy jsem se nedopídil žádného use case. Oficiální zdroje uvádějí pouze nějakou lame ukázku RSS - jo, tomu říkám funkčnost! Nikdy jsem neviděl žádný propagační screen cast, blog, který by se zabýval konkrétními funkcemi které by využívaly tohoto monstrozního a hyper všeschopného aparátu. Když jsem to chtěl zkusit sám, tak to buď slítlo nebo nic nenašlo. Poslední tečkou pak bylo, že při zadání čehokoliv do krunneru to na mě vyblilo tuny nějakých hexa-kdovíco-URL-hashů.
 22.6.2010 20:11
thingie | skóre: 8
22.6.2010 20:11
thingie | skóre: 8
 22.6.2010 20:20
Marek Bernát | skóre: 17
| blog: Arcadia
22.6.2010 20:24
thingie | skóre: 8
22.6.2010 20:32
Marek Bernát | skóre: 17
| blog: Arcadia
22.6.2010 20:20
Marek Bernát | skóre: 17
| blog: Arcadia
22.6.2010 20:24
thingie | skóre: 8
22.6.2010 20:32
Marek Bernát | skóre: 17
| blog: Arcadia
Čiže odpoveď je nie, ďakujem Ak teda nepredpokladáš, že ľudia budú tráviť všetok voľný čas tagovaním...
22.6.2010 20:40
thingie | skóre: 8
22.6.2010 20:46
Marek Bernát | skóre: 17
| blog: Arcadia
Nerozumiem, ako môže byť odpoveď áno bez toho, aby si mal niekde povedané "Na tomto obrázku je elektrická lokomotíva". To si ten Nepomuk akože vycucá z prsta?
Kopa podstatných informácii tam možno je (a napr. na dokumenty to môže stačiť), ale čo zistí Nepomuk bez tagovania z obrázkov/hudby/filmov? Len strojové záležitosti typu veľkosť, dominantná farba, dĺžka filmu a pod. ale to ty väčšinou nechceš. Tá hudba a filmy ešte ujdú, to niekto otaguje raz a zdieľa pre celý svet, takže amortizovaná námaha je zanedbateľná. Ale fotky? To fakt sa ti chce poriadne tagovať milión fotiek kopou tagov? Neverím
22.6.2010 20:58
thingie | skóre: 8
 23.6.2010 09:41
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
22.6.2010 21:04
Marek Bernát | skóre: 17
| blog: Arcadia
22.6.2010 21:11
thingie | skóre: 8
23.6.2010 09:41
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
22.6.2010 21:04
Marek Bernát | skóre: 17
| blog: Arcadia
22.6.2010 21:11
thingie | skóre: 8
Teda, první věc je, že běžní lidé milují katalogizace, třídění a všechny tyhle věci.Bežní ľudia milujú plochu, kam si môžu dať akýkoľvek súbor. Nepoznám žiadneho bežného človeka, čo by si v počítači triedil súbory naozaj dôsledne (a bežný človek už vôbec nepoužíva KDE a Nepomuk, takže to, že niekto bude v Nepomuk niečo tagovať im nijako nepomôže, keďže im to nebude fungovať a momentálne je otázne, či je aspoň vyriešená synchronizácia tých dát medzi rôznymi PC).
Když si třeba uložím nějakou fotku z novin nebo něco takovýho (protože tam jí už nikdy podruhý nenajdu…), tak ona už na tom webu popsaná je a ten brauzr to vidí, ale… nic. Ručně.To je platný bod pro Vás, ale opět zatím nevidím žádný use case, který by to realizoval.
Teda, první věc je, že běžní lidé milují katalogizace, třídění a všechny tyhle věci. Většina z nich to sice nebude dělat důsledně, ale hodně jich to bude milovat. Fakt.Spíš běžní lidé milují pořádek. Věci třídí, nikoliv kategorizují.
Druhá věc je, že když už máš velké strojově zpracovatelné databáze plné pracně sémanticky označkovaných dat, tak se ti s trochou nadsázky otvírá spousta nových možností jak s tím strojově pracovat dál.Říkal jsem už, že bych chtěl vidět nějaký use case? :)
Říkal jsem už, že bych chtěl vidět nějaký use case? :)Teda nie že by som 100% vedel čo píšem
, ale predstav si, že máš firmu, ktorá dostáva elektronické faktúry ako attachment v maile. A potrebuješ nájsť faktúru firmy Foo poslanú máji roku 2006. Integrovaním mailera a nepomuku by to malo byť ľahko realizovateľné, nie? Potrebuješ len aby mailer príchodzí mail podhodil nepomuku, ten na to poštve plugin, ktorý si z PDF vytiahne kľúčové slová a asociuje ich s tým mailom.
Koniec koncov viem si za desať rokov predstaviť aj plugin, ktorý z fotky rozpozná, či je na ňom tvár manželky alebo nie (ok, ženská tvár podobná tej, čo som v minulosti niekde otagoval "manželka") alebo či je v pozadí sneh a tým uľahčí nájdenie fotiek z minuloročnej lyžovačky.
Alebo tak nejak.
Integrovaním mailera a nepomuku by to malo byť ľahko realizovateľné, nie?Toto jsem cca popsal někde níže. Je to dost jednoduché a chytlavé, ale bohužel to není implementované. A to je ten problém.
Koniec koncov viem si za desať rokov predstaviť aj plugin, ktorý z fotky rozpoznáProč za 10, tohle funguje do jisté míry i dnes. Jenže zas se nenajde nikdo kdo by to zabalil a prodal.
23.6.2010 10:58
Marek Bernát | skóre: 17
| blog: Arcadia
Jj, súhlas. To sa zasa týka toho, čo som tu už niekde písal: posielať spolu so súborom metadáta. Ale aby to začalo fungovať, tak to musí podporovať prakticky všetok softvér, takže vo svojom živote to asi už neuvidím
Tohle adresářová struktura nedá.Proč ne?
obrazky/velke/lokomotivy
22.6.2010 20:48
thingie | skóre: 8
22.6.2010 20:49
Marek Bernát | skóre: 17
| blog: Arcadia
A čo ak sú niektoré z tých lokomotív fotené v Prahe a iné v Brne? Symlinky na
obrazky/mesta/praha
obrazky/mesta/brno
? A čo ak sa dajú katalogizovať podľa ďalších desiatich parametrov?
Výhody sémantiky sú nepopierateľné. Otázka je, kto bude ten otrok, ktorému sa to bude chcieť katalogizovať
A čo ak sú niektoré z tých lokomotív fotené v Prahe a iné v Brne? Symlinky naTohle trochu zavádíte. Lokomotiva v Praze nemá obvykle žádnou souvislost s městem Praha. Takže pokud budu chtít strukturovat dále, tak budu mít třebaobrazky/mesta/praha obrazky/mesta/brno?
obrazky/velke/lokomotivy/prahaProtože tohle je pro mne přirozené dělení. Ne-stromová dělení jsou pro člověka hodně těžko stravitelné, proto třeba je něco jako /sys pro většinu lidí nepřehledné bludiště. Jediný problém může být v tom, že různí lidé můžou mít jiné preference, tj. každý si vytvoří nějakou (různou) stromovou strukturu. Jenže to je úplně jiný problém.
A čo ak sa dajú katalogizovať podľa ďalších desiatich parametrov?Dáte jim pořadí ve stromu a hotovo. Ale hloubka 10 je pro normálního člověka dost za hranicí držení mentální moči.
Výhody sémantiky sú nepopierateľné. Otázka je, kto bude ten otrok, ktorému sa to bude chcieť katalogizovaťSémantika ale není tagování. A tagovat se opravdu nikomu nechce. Zvlášť s vyhlídkou současně poskytovaného "bezpečí" těch tagů.
22.6.2010 21:44
thingie | skóre: 8
23.6.2010 08:33
thingie | skóre: 8
22.6.2010 22:03
Marek Bernát | skóre: 17
| blog: Arcadia
Ok, tak iný príklad, nemusí to byť zrovna lokomotíva, to nie je moja šálka kávy. Mám napríklad fotku kamarátov za určitého počasia, v určitom meste. Ideálne by som jej dal ako tagy všetky mená, počasie, mesto, prípadne ďalšíe veci. O rok na to si budem chcieť pozrieť fotky, kde sa nachádza kamarát ten a ten, alebo si pozrieť fotky v daždi v Prahe. Ako toto dosiahnem s adresárom, to fakt netuším Use caseov (a veľmi zaujímavých) sa dá vymyslieť milión, ale vždy to naráža na problém tagovania.
Prečo by sémantika nebolo tagovanie? Sémantika je o významoch a súvislostiach (ontológii) a presne tú Vám tagy dajú.
 22.6.2010 23:12
Bilbo | skóre: 29
22.6.2010 23:38
Marek Bernát | skóre: 17
| blog: Arcadia
22.6.2010 23:12
Bilbo | skóre: 29
22.6.2010 23:38
Marek Bernát | skóre: 17
| blog: Arcadia
To ale nerieši ten najpodstatnejší problém: tie tagy musí niekto zadať. Už je vcelku šumák, či ich zadáva do Nepomuku, do nejakého súboru, databázy, alebo inam (samozrejme, z hľadiska ďalšej manipulácie a vyhľadávania to jedno byť nemusí).
digiKam je pro me killer aplikace zejmena diky metadatum.
22.6.2010 23:44
Marek Bernát | skóre: 17
| blog: Arcadia
lsattr a chattr, ext3 to umí bez problémů, jen je potřeba mount volba user_xattr. Používá to třeba Samba na ukládání DOS atributů nebo rozšířených ACL. Výhoda je, že lze takové atributy nativně zálohovat, i když na to většina zálohovcích nástrojů nepamatuje, nebo alespoň ne ve výchozí konfiguraci.
Pokud vím, tak MAC OS právě extended atributy používá k uložení MIME typu.
Problém je, co se stane, když takový soubor pošle člověk mailem, uploaduje někam na web atd. (teoreticky se může celou dobu informace o MIME typu uchovat, ale v praxi to je problém).
23.6.2010 08:26
Marek Bernát | skóre: 17
| blog: Arcadia
Presne tretí odsek je to, o čom som hovoril. Ja by som chcel, aby existoval nejaký vcelku jednotný formát súborov (otvorený štandard), ktorý si tie dáta práve zachová aj po ceste cez rôzne servery a naprieč operačnými systémami. Tj., aj protokoly ako FTP a HTTP by museli tie metadáta nejak podporovať. Inak to nemá zmysel a treba po každom prenesení znova všetky metadáta vypĺňať ručne. V praxi je to zatiaľ samozrejme nereálne, ale OS a programy sa stále zlepšujú, tak možno raz... kto vie
Mám napríklad fotku kamarátov za určitého počasia, v určitom meste.Já si myslím, že jste tím nezměnil vůbec nic.
fotky/franta v praze/chčije fotky/franta v praze/svítí sluníčkoJak jsem říkal, není těžké do té struktury vložit pořadí. Vy to furt tlačíte směrem, aby bylo něco jako
fotky/franta/praha/chčije fotky/praha/chčije/franta fotky/chčije/praha/frantaatd. ale jak vidíte tak je v tom bordel kde se ani prase nevyzná a IMHO si lidi prostě takovéhle struktury nevytváří ani v hlavě natož na disku.
Use caseov (a veľmi zaujímavých) sa dá vymyslieť miliónTak s něčím zajímavým přijďte.
Prečo by sémantika nebolo tagovanie? Sémantika je o významoch a súvislostiach (ontológii) a presne tú Vám tagy dajú.Sémantika není tagování coby činnost. Pojmenování věcí prostě nějaké je, souvislosti existují, ale ručně počítač učit co je co je přístup programátora nebo knihovníka, ale ne člověka co přitáhl 200 fotek z dovolené. "dovolená 2010 červenec praha chčije franta honza sloup moucha dlažba václavák turisti" hurá už mám otagovanou jednu fotku.
23.6.2010 08:19
Marek Bernát | skóre: 17
| blog: Arcadia
A ja si myslím, že Vy ste vôbec nepochopili, čo je to tag a všetko tlačíte do adresárovej štruktúry, ktorá nikoho nezaujíma a je na to úplne nevhodná Choďte sa niekedy pozrieť napr. na facebook. Tam majú ľudia možnosť otagovať fotku a často dajú ako tagy všetkých ľudí, čo na nej sú. Následne nie je problém si každého človeka vyhľadať, bez ohľadu na to, kde tie fotky sú (u ktorého konkrétneho používateľa). Ukážte mi, ako by ste toto riešili adresármi Adresár je niečo ako dedičnosť (dáta -> knihy -> beletria). Tu žiadnu dedičnosť nemáte, všetky tagy sú rovnako dobré a nemá zmysel mať jeden vyššie postavený ako iný. Skúste to konečne pochopiť, inak táto diskusia nemá zmysel...
Sémantiku má v hlave človek a to je pre ďalšie spracovanie úplne irelevantné. Treba to nejak naučiť ten počítač. A vzhľadom k tomu, že nemáme A.I., tak tagovanie je asi najpriamočiarejšia možnosť. Tak či onak, mohli by ste konečne prestať s naťahovaním sa o slovíčka
Adresár je niečo ako dedičnosť (dáta -> knihy -> beletria).Není to dědičnost, adresář je jen upřesnění dotazu. A je dost jedno jestli se dotazuju na tagy nebo na jména skutečných adresářů. Takováto posloupnost dotazování je u jednoho člověka málokdy tak turbulentní, aby nešla reprezentovat skutečnými adresáři. To proto, že člověk si ty věci v hlavě organizuje do stromu, ne do obecného grafu.
Sémantiku má v hlave človek a to je pre ďalšie spracovanie úplne irelevantné.Naopak, na tom záleží nejvíc.
A vzhľadom k tomu, že nemáme A.I., tak tagovanie je asi najpriamočiarejšia možnosť.Nevím jestli nej, ale ano, manuální práce je velmi jednoduchá možnost, ale také jedna z těch méně zajímavých.
23.6.2010 11:34
Marek Bernát | skóre: 17
| blog: Arcadia
To bol len príklad, nemusí tam byť viac ľudí. To isté môžem urobiť na lokále. Ale je jasné, že hlavné výhody sémantického desktopu sú v zdieľaní. Nakoľko toto Nepomuk rieši netuším.
Nie je to jedno z toho dôvodu, že nie je jasné, akú adresárovú štruktúru by tie tagy mali mať.
Ktorý človek? To je nejaká silná generalizácia. Ja napríklad mám často v hlave graf. A ostatne každá trošku zložitejšia myšlienka, alebo teória sa inak než grafom vyjadriť nedá. Stačí si zobrať už ekvivalenciu dvoch tvrdení Že sa na všetko snažíte napasovať storočnú metodológiu danú štruktúrov bežných filesystémov, to je Váš problém; chce to trochu väčší rozhľad
Ale počítač ani zbytok sveta Vám do hlavy nevidí, takže je irelevantné, čo tam máte. Relevantné a zaujímavé to začne byť až vtedy, keď tie informácie odovzdáte niekomu inému.
Súhlasím, manuálna práca nie je ideálna (mne osobne by sa tagovať veľmi nechcelo). Máte lepší návrh?
To isté môžem urobiť na lokále.Dejte příklad.
Nie je to jedno z toho dôvodu, že nie je jasné, akú adresárovú štruktúru by tie tagy mali mať.Tu kerou používáte při dotazování.
Ja napríklad mám často v hlave graf.Příklad?
A ostatne každá trošku zložitejšia myšlienka, alebo teória sa inak než grafom vyjadriť nedá. Stačí si zobrať už ekvivalenciu dvoch tvrdeníSouvisí tohle s původním problémem? (Kategorizace fotek)
na všetko snažíte napasovať storočnú metodológiu danú štruktúrov bežných filesystémovOrganizace FS následuje vzorce organizace které vídáme často kolem sebe (stromová struktura). Já nic na nic nepasuju. Já tvrdím, že problém subjektivní kategorizace fotek (nebo čehokoliv) obecně používá tento vzorec a ergo že adresářová struktura je na to vhodný nástroj.
Máte lepší návrh?Jistě. Spousta dat se dá vyčíst automaticky. Například znovu z té pitomé adresářové struktury. Nebo z informace kdo mi fotky poslal. Nebo kdy. Nebo ze sledování chování uživatele. Na co kouká často, na co míň, co dělá předtím a potom. Tyhle všechny věci např. webové vyhledávače (a jejich adaptace na desktop) umí dělat samy, ruční popisování stránek klíčovými slovy je pasé jak kalhoty do zvonu... Dělá něco z toho sémantický nepomuk?
23.6.2010 13:36
Marek Bernát | skóre: 17
| blog: Arcadia
Už som Vám ho dal: nájsť fotky, na ktorých je kamarát XY.
Pri dotazovaní použijem taký dotaz, aký sa mi zrovna hodí. Ale adresárová štruktúra je len jedna.
Príkladom je hocijaká fotka, ktorá sa nedá rozumne katalogizovať podľa jedného parametra.
Samozrejme, že súvisí. Tomáš je na fotkách A, B a C a na fotke A je Tomáš a Matúš. Všetko (osoby aj fotky) sú len dáta a relácie na nich sú vždy symetrické, takže už z toho dôvodu je stromová štruktúra nevhodná (orezávate jeden smer tej relácie).
A kde všade vidíte tú stromovú štruktúru? Stačí sa pozrieť na ľubovoľnú matematickú teóriu (alebo obecnejšie vedu). Tvrdenia sú pospájané implikáciami a vznikne Vám z toho dosť brutálny graf, ktorý rozhodne nie je strom. Obecnejšie, ľubovoľná aspoň trochu zložitejšia množina dát vám vytvorí cyklickú štruktúru. FS podľa mňa ani tak nesleduje vzorce chovania, ako ich násilne všetkým vnucuje. Pochopiteľne, že keď na disku nemám možnosť katalogizovať dáta inak než pomocou stromovej štruktúry, tak ich tam nejako narvem. Ale nikdy mi to nepripadalo prirodzené a určite sa to dá robiť lepšie (napr. aj pomocou tagov). Pekne to ukazuje Gmail, kde mám konečne možnosť katalogizovať maily pomocou tagov. Adresáre sú prežitok...
Z tej adresárovej štruktúry (fotky/2009/Praha) rozhodne nevyčítam, že tam niekde je zapadnutý Mišo alebo Jozef, ktorého fotky by som si rád pozrel. Vyčítate z toho len úplne nezaujímavé veci. Podobne z toho sledovania používateľov. Dôležité dáta sú inde.
Kľúčové slová sú pasé? [citation needed]
Netuším, čo z toho robí Nepomuk a nezaujíma ma to. Bavím sa o tom, či sa niektoré veci nedajú robiť lepšie, než sa momentálne robia. Namiesto zastávania sa prehistorických technológií, ktoré tu predvádzate Vy...
23.6.2010 11:48
Marek Bernát | skóre: 17
| blog: Arcadia
Flickr zas pre zmenu nepoznám ja Ale na FB to funguje celkom dobre. Aj keď je to tam zamerané hlavne na osoby (a tag je typicky asociácia rovno s iným FB účtom) a pre tento účel to funguje vynikajúco.
I středně velká firma produkující ročně několik tisíc dokumentů si obvykle vystačí s rozumnou adresářovou strukturou a archivem.Záleží co si představujete pod slovem "vystačí". Moje zkušenost z řady firem, kterými jsem prošel je tristní, relevatní dokumenty buď putují emailem, nebo se prostě doptáte, brain base ontology sytem & orátlní tradice. Pak jen doufejte, že vám dotyčný z firmy neodejde, dokumenty pak můžete prakticky smazat, než se se v nich nováček stačí vyznat, zastarají a jsou zralé do archivu. Nebo že vám je někdo úmyslně nezatají. Nebo se na nějaké prostě zapomene. Nejlepší co jsem zatím poznal byl systém založený na wiki nebo Sharepoint, což jsou takové hodně primitivní ontologické systémy, mají vyhledávač a linky v textu, alespoň něco.
Navíc se nezdá, že by nepomuk sedící v ~/.kde oplýval nějakými schopnostmi se sdílet třeba s jinými uživateli ve firmě.Kde-Nepomuk je technologie desktopová, co uživatel to vlastní databáze z vlastního písečku, čili nic o síťovém sdílení. To se musíte dívat po technologiích s přívlastkem "enterprise". Musí se pak řešit bezpečnost, utajení, a veškerá ta multiuživatelská sranda.
Nikdy jsem se nedopídil žádného use case.Tak nějaké se tu v dikusi snad už povalují, v článku pravda moc ne.
Kde-Nepomuk je technologie desktopová, co uživatel to vlastní databáze z vlastního písečku, čili nic o síťovém sdílení. To se musíte dívat po technologiích s přívlastkem "enterprise". Musí se pak řešit bezpečnost, utajení, a veškerá ta multiuživatelská sranda.Plno lidí má počítač+notebook / tablet / smartphone apod. A chce mít třeba fotky a dokumenty na přístupné více zařízeních. Podle mě je tedy potřeba to řešit. Zatím ale není uspokojivě vyřešená ani prostá synchronizace souborů mezi takovými různými zařízeními.
 23.6.2010 18:22
Nicky726 | skóre: 56
| blog: Nicky726
23.6.2010 18:22
Nicky726 | skóre: 56
| blog: Nicky726
 22.6.2010 10:14
Jakub Lucký | skóre: 40
| Praha
22.6.2010 10:14
Jakub Lucký | skóre: 40
| Praha
 22.6.2010 08:35
Freeman
| blog: freeemans
22.6.2010 09:58
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
22.6.2010 08:35
Freeman
| blog: freeemans
22.6.2010 09:58
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
 22.6.2010 14:14
tomboytom-deviant | skóre: 7
| blog: lojdovo
| .com
22.6.2010 14:14
tomboytom-deviant | skóre: 7
| blog: lojdovo
| .com
 22.6.2010 16:36
Vykook | skóre: 23
| blog: Tomas
22.6.2010 16:36
Vykook | skóre: 23
| blog: Tomas
 22.6.2010 10:36
danaketh | skóre: 6
| blog: Sick Mind
| Praha
22.6.2010 11:45
Vykook | skóre: 23
| blog: Tomas
Od ty doby co maj soubory tagy, url z ktere jsem je stahl, geolokaci a muzu vsechno snadno najit, tak mam skoro vsechno v adresari "Bordel", kterej bobtna a bobtna. Otazka jestli to je dobre nebo ne.
22.6.2010 10:36
danaketh | skóre: 6
| blog: Sick Mind
| Praha
22.6.2010 11:45
Vykook | skóre: 23
| blog: Tomas
Od ty doby co maj soubory tagy, url z ktere jsem je stahl, geolokaci a muzu vsechno snadno najit, tak mam skoro vsechno v adresari "Bordel", kterej bobtna a bobtna. Otazka jestli to je dobre nebo ne.
Jaký je současný stav sémantického desktopu v operačním systému GNU/Linux?
Já to ani nečetl, neboť:
a) mám mezery ve vzdělání, když nevím, že GNU/Linux má v sobě desktop, a dokonce sémantický,
b) autor má nějakou mezeru ve vzdělání.
Je smutné přestat číst po první větě. :'(
22.6.2010 16:22
thingie | skóre: 8
22.6.2010 16:40
thingie | skóre: 8
Mám KDE 3.5To je mi líto. Každopádně. Konfig je úplně stejný, tak se to jistě dá zakázat v něm. Nebo to vyhodit z nějakého autostartu. Nebo taky klidně odinstalovat. Nějaký expert přes středověk bude snad tušit, no.
apt-get install kdebase-bin-kde3 apt-get autoremove
22.6.2010 17:20
thingie | skóre: 8
Protože ten checkbox v ovládacím centru co přesně tohle dělá je nějaká magická nedokumentovaná funkce, asi.Tak snadné to nebude. Už nyní neběží KMail nebo Kopete bez Akonadi. Od verze 4.5.1 bude KMail záviset i na Nepomuku, jestli se nepletu.
22.6.2010 19:06
thingie | skóre: 8
22.6.2010 20:29
thingie | skóre: 8
uživatelům je to naprosto jedno, protože ti chtějí jenom důvody proč [na to] nadávatJá zde spíš vidím zájem uživatelů. Každý druhý se ptá, na co to je. :)
A samozřejmě, za rok nebo dva Apple nebo někdo takovej přijde s fičurou, která přesně něco takového k implementaci potřebuje, a rozkráká se zase půlka světa, proč to v Linuxu zase nejde a nejni.Což ale bude pravda, protože na tom Applu člověk aspoň přesně uvidí "co to umí", zatímco na Linuxu to "bude napůl", "bude to umět všechno a nic" a když si podám bug report tak mě pošlou do prdele.
22.6.2010 20:42
thingie | skóre: 8
Jenže tady prostě nejde tři roky něco v tajném bunkru vyvíjet a pak s velkou slávou vyrolovat. I ten Apple by měl v nějaké fázi jenom něco napůl.Jsem rád že jste to napsal. Protože to je přesně ten model bunkr, na kterém jede KDE. Tři roky (nebo i víc) si připravujou "framework", aniž by ho kdokoliv používal? Come on. Dodat věc napůl znamená: podívejte, nový KMail umí k obrázkům přilepit informaci o tom kdo je poslal a nový Gwenview/Dolphin je umí podle toho hledat. Sice to ještě neumí dotaz "všechny obrázky od franty s lokomotivou" ale už to umí "všechny obrázky od franty". Kvůli tomu druhému dotazu musíme ještě zapracovat na frameworku takže za 3 měsíce dostanete beta na vyzkoušení a ostrou verzi tak za půl roku.
22.6.2010 21:55
thingie | skóre: 8
Jasně, je to zoufalý, ale co jako dělat?Vždyť to říkám, klidně ať to dodají poloviční, ale v tom smyslu, že funguje polovina uživatelem dostupných funkcí. Pokud budou donekonečna přepisovat jádro, aniž by měli jedinou funkcionalitu pro uživatele, tak se to nepohne ani o píď a buou to vyhozený prachy a úsilí. Klidně ať ty metadata cpou do texťáku, ať je to hloupý, ale ať si to může uživatel osahat a říct: tohle se mi líbí/nelíbí, chci/nechci tohle a tamto. Od toho teprv se pak může odvíjet směr vývoje backendu. Třeba přijdou na to, že celou dobu řešili nesprávný problém™ a ani bych se nedivil.
23.6.2010 08:36
thingie | skóre: 8
V delfínovi nebo gwenview to už řádku verzí je, takže ta funkcionalita tam nějaká byla už delší dobu.Nevím co myslíte tím "to", ale ten případ s KMailem to asi nebude? Ono je problém právě najít to "to", protože to je ten use case, ten prodejní bod. A ty jaksi stále chybí.
Akorát to bylo tak rozbité, že to skoro nešlo použít, takže není tohle právě ten případ který volá po přepsání backendu?Pokud je to rozbité tak to nemá v "release" verzi software přece co dělat. Jinak uživatel ztratí důvěru v ten kus software a nebude to používat. Což je zhruba pozorované chování. A jestli se má kvůli tomu přepsat přední, prostřední, nebo zadní část toho SW už musí určit programátoři. Ale výsledek by měl být kus programu, který funguje odzhora dolů (s důrazem na interface k uživateli) u nějaké konkrétní funkce, nikoliv kus programu, který má potenciál mít těch funkcí sto padesát ale ani jedna nefunguje/nemá UI.
Tahle diskuse celkem zřetelně ukazuje, že uživatelům je to naprosto jedno, protože ti chtějí jenom důvody proč [na to] nadávat.Táto (a aj ostatné) diskusie zreteľne ukazuje, že používatelia chcú vedieť, k čomu vlastne to slúži a prečo to teda majú chcieť (a aj to, prečo to bude povinná závislosť pre niektoré aplikácie).
23.6.2010 13:12
Vykook | skóre: 23
| blog: Tomas
23.6.2010 14:43
Vykook | skóre: 23
| blog: Tomas
Tak snadné to nebude. Už nyní neběží KMail nebo Kopete bez Akonadi. Od verze 4.5.1 bude KMail záviset i na Nepomuku, jestli se nepletu.To nie je pravda. Ak sa bavime o checkboxe spominanom tu, tak rozhodne bez neho Kopete funguje v pohode. Je sice pravda, ze sa to nieco s Akonadi snazilo robit, ale ked som to vypol, tak to v pohode rozdychalo a fungovalo dalej.
22.6.2010 19:13
thingie | skóre: 8
Pár takových databází je volně k dispozici. Například databáze WordNet (hledejte stenojmenný balík):
$ wn beer -treen
Hyponyms of noun beer
1 sense of beer
Sense 1
beer
=> draft beer, draught beer
=> suds
=> lager, lager beer
=> Munich beer, Munchener
=> bock, bock beer
=> light beer
=> Oktoberfest, Octoberfest
=> Pilsner, Pilsener
=> malt, malt liquor
=> ale
=> Weissbier, white beer, wheat beer
=> Weizenbier
=> Weizenbock
=> bitter
=> Burton
=> pale ale
=> porter, porter's beer
=> stout
=> Guinness
23.6.2010 23:09
Nicky726 | skóre: 56
| blog: Nicky726
22.6.2010 19:37
Nicky726 | skóre: 56
| blog: Nicky726
 23.6.2010 11:39
theo | skóre: 15
| Rožnov ... hádej který?
23.6.2010 11:39
theo | skóre: 15
| Rožnov ... hádej který?
vy nemate radi nove technologie?
Jak které. Je-li jasné, co to vlastně je a k čemu by mi to mohlo být dobré, tak vesměs ano. Ale zásadně mám nedůvěru k technologiím, o kterých se po přečtení deseti oslavných článků sice dozvím, jak jsou strašně super a jak se bez nich nedá žít, ale stejně pořád nevím, co to vlastně je a k čemu by mi to mohlo být dobré. A přesně do téhle kategorie "sémantický desktop".
23.6.2010 12:01
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
23.6.2010 23:17
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
Ale je to nějaká změna .. dříve se diskutovalo omezeně v novinách nebo e-mailem ..
24.6.2010 10:22
theo | skóre: 15
| Rožnov ... hádej který?
Na vec se da ovsem divat i odjinud: to ze zatim v masovem meritku netusime k cemu by takova vec mohla slouzit (protoze implementace a samotna technologie je zatim v plenkach) neznamena, ze nebude naprosto zasadnim zlomem za 5 let.
Moje zkušenost je taková, že si nevzpomínám na technologii, o které by se psaly takové oslavné a obsahově prázdné články a která by se pak ukázala opravdu významnou nebo dokonce převratnou. Naopak, o těch, které převratné byly, se většinou začaly oslavné články psát až poté, co se prosadily (bez mediální masáže).
Pokud je mi znamo, tak KDE a jeho soucasti jsou schopne ± fungovat i bez NEPOMUKu.Hehe, ne.
Issue#1: není pořádek ve věcech  24.6.2010 18:23
Jakub Lucký | skóre: 40
| Praha
24.6.2010 18:23
Jakub Lucký | skóre: 40
| Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 23.6.2010 11:36
23.6.2010 11:36