Dnes ve 12:00 byla spuštěna první aukce domén .CZ. Zatím největší zájem je o dro.cz, kachnicka.cz, octavie.cz, uvycepu.cz a vnady.cz [𝕏].
JackTrip byl vydán ve verzi 2.3.0. Jedná se o multiplatformní open source software umožňující hudebníkům z různých částí světa společné hraní. JackTrip lze instalovat také z Flathubu.
Patnáctý ročník ne-konference jOpenSpace se koná 4. – 6. října 2024 v Hotelu Antoň v Telči. Pro účast je potřeba vyplnit registrační formulář. Ne-konference neznamená, že se organizátorům nechce připravovat program, ale naopak dává prostor všem pozvaným, aby si program sami složili z toho nejzajímavějšího, čím se v poslední době zabývají nebo co je oslovilo. Obsah, který vytváří všichni účastníci, se skládá z desetiminutových
… více »Program pro generování 3D lidských postav MakeHuman (Wikipedie, GitHub) byl vydán ve verzi 1.3.0. Hlavní novinkou je výběr tvaru těla (body shapes).
Intel vydal 41 upozornění na bezpečnostní chyby ve svých produktech. Současně vydal verzi 20240514 mikrokódů pro své procesory řešící INTEL-SA-01051, INTEL-SA-01052 a INTEL-SA-01036.
Společnost Raspberry Pi patřící nadaci Raspberry Pi chystá IPO a vstup na Londýnskou burzu.
Google na své vývojářské konferenci Google I/O 2024 představil řadu novinek. Keynote byl věnován umělé inteligenci (DeepMind, Gemini, Responsible AI).
V Gitu bylo nalezeno 5 zranitelností. Opraveny jsou ve verzích 2.45.1, 2.44.1, 2.43.4, 2.42.2, 2.41.1, 2.40.2 a 2.39.4. Útočník může připravit repozitář tak, že při jeho klonování (git clone) může dojít ke spuštění libovolného kódu.
Virtualizační softwary VMware Workstation Pro a VMware Fusion Pro jsou nově pro osobní použití zdarma. Softwary VMware Workstation Player a VMware Fusion Player končí.
Linuxová distribuce Endless OS (Wikipedie) byla vydána ve verzi 6.0.0. Přehled novinek i s náhledy v příspěvku na blogu, poznámkách k vydání a také na YouTube.
Když se mi podařilo přemluvit Vojtu Zeiska, aby začal pomáhat s českými překlady openSUSE, tak jsme narazili na jeden malý problém. Tím je, že nevím o žádném praktickém návodu, jak to chodí s překládáním aplikací. Co je potřeba udělat, jak funguje KBabel a tak dále. Rozhodl jsem se proto jeden takový úvod do překládání napsat. Praktické ukázky jsou založeny na tom, jak funguje openSUSE i18n (Internationalization), ale neměl by být problém je aplikovat i na jiné projekty.
Většinou je úkolem člověka, který se stará o překlady, aby byly *.po soubory v trunku (testovací větev distribuce, u jiných projektů prostě nejčerstvější verze zdrojových kódů) co nejvíce aktuální. Proto to není vaše starost, ale pokud byste narazili na neaktuální zdrojový .po soubor, měli byste se postarat o jeho aktualizaci pomocí nástroje msgmerge, jeho užití je vskutku jednoduché.
msgmerge def.po ref.pot
Kde def.po je nejaktuálnější soubor s českým překladem z trunku a ref.pot je soubor vygenerovaný ze zdrojových kódů překládaného programu. V případě openSUSE najdete def.po soubory na stránkách i18n.opensuse.org, kde si jednoduše vyberete projekt (yast nebo lcn) a v něm příslušný soubor, který si přes webové rozhraní k SVN repozitáři stáhnete. Volitelně můžete také použít příkaz svn ke stažení celého Subversion repositáře. Tuto možnost použijete, pokud to s překlady myslíte vážně. Kvůli jednomu překladu je zbytečné stahovat celý repositář a naopak je zbytečné neustále navštěvovat stránky, pokud překládáte pořád, nebo máte vlastní SVN účet (o ten si musíte zažádat a dovolí vám přímo uploadovat překlady na server, v případě openSUSE se o správu účtů do českého překladového SVN stará Klára Cihlářová).
Stažení repositáře provedete příkazem:
svn co https://forgesvn1.novell.com/svn/suse-i18n/trunk/ trunk
Po stažení vám vznikne adresář trunk a v něm pro vás zajímavé podadresáře lcn a yast. V těchto již najdete jednotlivé jazykové soubory roztříděné podle jazyka, ke kterému přísluší. V případě openSUSE se používá označení podle příslušné ISO 639 zkratky. České překlady jsou tedy umístěny v podadresáři cs.
Chcete li přeložit jazykový soubor ke knihovně ZYpp, tak jej najdete v adresáři trunk/lcn/cs/po/. Soubor samotný má název zypp.cs.po. Pokud byste chtěli provést aktualizaci oproti nejnovějšímu souboru zypp.pot, tak to učiníte následujícím příkazem:
msgmerge -U lcn/cs/po/zypp.cs.po lcn/50-pot/zypp.pot
Pro ostatní programy je příkaz analogický. Když máte vytvořenu nejnovější verzi jazykového souboru, je potřeba jej přeložit. To můžete učinit například pomocí programu KBabel z KDE, který najdete například v balíčku kdesdk3-translate (nainstalujete jej pomocí zypper install kdesdk3-translate). KBabel spustíte příkazem kbabel. Aby v něm byl soubor rovnou otevřen, stačí jeho název předat jako parametr například takto:
kbabel lcn/cs/po/zypp.cs.po
Při pohledu na okno programu vidíte ve stavovém řádku, že soubor obsahuje 12 nepřeložených řetězců a žádný fuzzy (fuzzy je druh řetězce, který byl automaticky spárován pomocí nástroje msgmerge a může obsahovat malé chybičky nebo může být i celý špatně. Jedná se tedy o řetězec, který musí být zkontrolován, a takto označené řetězce by se ve výsledném .mo souboru neměly vyskytovat). Celkem obsahuje 862 řetězců.
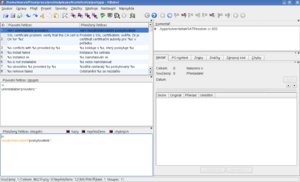
V nástrojové liště je tlačítko s popiskem "Následující fuzzy, nebo nepřeložený", které vás automaticky přesune na další řetězec, který je potřeba přeložit nebo zkontrolovat. Levá část hlavního okna je rozdělena na 3 části. První, horní část obsahuje ID řetězce, náhled originálního textu a náhled přiřazeného překladu. Druhá část obsahuje kompletní originální text a třetí část kompletní překlad, občas i včetně kontextu, který se nepřekládá. Tento kontext bývá přítomen například u překladu souboru update-desktop-files-kde.cs.po.
V pravé části je k dispozici také spousta užitečných informací. V políčku komentář je většinou k dispozici cesta ke zdrojovým souborům, ve kterých se tato fráze vyskytuje, včetně čísla řádku. Také pokud dal programátor k dispozici nějaký komentář, tak ten bývá v tomto okně zobrazen. Pomocí záložek se dále dá přepínat na jednotlivé funkce programu KBabel. Záložka "Hledat" zobrazuje již použité překlady označených slov, pokud si je necháte vyhledat pomocí ikony vlajky s lupou v nástrojové liště. Ta provede i automatické stažení slovníku ze stránek KDE (či jiného, pokud si změníte patřičné nastavení).
Po přeložení je vhodné překlad řádně zkontrolovat. To se provádí několika způsoby. Nejdříve se hodí alespoň pohledem projet všechny zprávy, jestli se vám v nich nepodaří nalézt nějaké překlepy nebo chyby. Dále je potřeba zkontrolovat .po soubor z hlediska kvality samotného souboru. Tuto kontrolu spustíte pomocí menu Nástroje -> Ověření -> Provést všechny kontroly nebo klávesovou zkratkou CTRL+E. Pokud byly nalezeny nějaké chyby, je vhodné se přepnout na záložku s názvem Chyby a po té jednotlivé chybné záznamy ručně projít pomocí tlačítka Další chyba v nástrojové liště. V záložce Chyba se objeví, jaký problém byl nalezen. Velice častým problémem bývá nedodržení interpunkce nebo anglický text v překladu (občas je anglický originál shodný s českým překladem zcela úmyslně).
Pokud je váš překlad dokončen a všechny doposud nalezené chyby jsou opraveny, je potřeba přistoupit k další fázi testování, a tou je zkouška ve skutečné aplikaci. Uložte si váš překládaný soubor a pomocí příkazu
msgfmt soubor.po
proveďte jeho překlad na .mo soubor. Napříkad takto:
msgfmt lcn/cs/po/zypp.cs.po -o lcn/cs/po/zypp.cs.mo
Vytvořený soubor (například lcn/cs/po/zypp.cs.mo) pak zkopírujte do adresáře /usr/share/locale/cs/LC_MESSAGES/*.mo (podle názvu souboru). V našem příkladu je to tedy soubor /usr/share/locale/cs/LC_MESSAGES/zypp.mo. A spusťte si aplikaci, které patří přeložený soubor. V našem příkladu se jedná o knihovnu ZYpp, kterou využívá program zypper, správce balíčků v YaSTu a možná i další aplikace.
Pokud během testování nenarazíte na žádný problém, je načase poslat přeložený soubor některému z překladatelů e-mailem (v případě openSUSE na maillist opensuse-cs@opensuse.org). Ten jej zkontroluje, pošle vám svůj názor na kvalitu překladu, abyste se mohli příště třeba zlepšit, případně vám rovnou nabídne SVN přístup a překlad odešle do repositáře. Pak už vám bude k poslání překladu stačit napsat jen
svn commit -m "Nějaký komentář, nejlépe anglicky"
Pokud používáte k udržování lokální kopie překladů Subversion, nezapomeňte udržovat své překlady aktualizované pomocí příkazu svn up. Chcete-li z nějakého důvodu udržet překlady konzistentní s těmi microsoftími, pak doporučuji stránku Microsoft Language - Search Tool (za odkaz bych chtěl poděkovat Kyosukemu).
Popis pokročilejších funkcí programu KBabel: automatické překlady, slovníky, kompendia atp.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 15.7.2008 00:17
Kamil Páral | skóre: 13
| blog: Kamil Páral
| Brno
15.7.2008 00:17
Kamil Páral | skóre: 13
| blog: Kamil Páral
| Brno
$ msgfmt -cv soubor.po
Provede to i základní kontrolu správnosti souboru.
 15.7.2008 10:32
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
15.7.2008 10:32
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
 15.7.2008 12:04
freshmouse | skóre: 42
| blog: Bruno Banány
15.7.2008 12:04
freshmouse | skóre: 42
| blog: Bruno Banány
Když se mi podařilo přemluvit Vojtu Zeiska, aby začal pomáhat s českými překlady openSUSE, tak jsme narazili na jeden malý problém.Pak mě ještě zarazil odkaz na MS a PR OpenSUSE. Tenhle článek se mi zkrátka vůbec nelíbil (navíc byl krátký).
 15.7.2008 12:06
freshmouse | skóre: 42
| blog: Bruno Banány
15.7.2008 12:06
freshmouse | skóre: 42
| blog: Bruno Banány
Každopádně jsem tam neměl nic jakoProto je ten úvod "upovídaný". Nicméně uznávám, že tento článek je na hraně.
Pak mě ještě zarazil odkaz na MSJe to užitečný odkaz
 (a nepřipadá Ti to divné?)
A to nejspíš i přesto, že článek o lokalizacích fungující pro Ubuntu by se nedal použít na nic jiného než na lokalizace pro Ubuntu, kdežto tohle se dá s trochou snahy použít i na všechno ostatní. (I když samozřejmě, tu snahu to bude chtít, článek je opravdu trochu moc stručný a neučesaný, to jsou zcela legitimní výhrady. Ale shazování takhle nefér způsobem si doopravdy nezaslouží.)
Někdy si říkám, že se nemá zevšeobecňovat... a jindy zas, že je divné, že kdykoliv je někde potkám, vypadá to, že Ubunťáci se snaží veškerou práci na distribuci ze všech sil schovávat pro sebe a když už se někdo cizí někdy přece jen dostane k nějakému jejich patchi do balíku, zjistí brzy, že by si ho měl raději napsat sám... a čas a prostředky ušetřené odváděním nekvalitní práce pak mohou věnovat propagaci (což je osvědčený postup, MS to dělá od samého začátku) a to i na úkor ostatních distribucí (což je nejúčnnější). Ale samozřejmě je to jen paranoia, protože jsem jen měla smůlu na těch pár pochybných patchů z tisíce a pár zcela výjimečných Ubunťáků
No nic. Holt je jim přáno, já jdu radši zase na ty patche pro openSUSE
15.7.2008 15:38
freshmouse | skóre: 42
| blog: Bruno Banány
(a nepřipadá Ti to divné?)
A to nejspíš i přesto, že článek o lokalizacích fungující pro Ubuntu by se nedal použít na nic jiného než na lokalizace pro Ubuntu, kdežto tohle se dá s trochou snahy použít i na všechno ostatní. (I když samozřejmě, tu snahu to bude chtít, článek je opravdu trochu moc stručný a neučesaný, to jsou zcela legitimní výhrady. Ale shazování takhle nefér způsobem si doopravdy nezaslouží.)
Někdy si říkám, že se nemá zevšeobecňovat... a jindy zas, že je divné, že kdykoliv je někde potkám, vypadá to, že Ubunťáci se snaží veškerou práci na distribuci ze všech sil schovávat pro sebe a když už se někdo cizí někdy přece jen dostane k nějakému jejich patchi do balíku, zjistí brzy, že by si ho měl raději napsat sám... a čas a prostředky ušetřené odváděním nekvalitní práce pak mohou věnovat propagaci (což je osvědčený postup, MS to dělá od samého začátku) a to i na úkor ostatních distribucí (což je nejúčnnější). Ale samozřejmě je to jen paranoia, protože jsem jen měla smůlu na těch pár pochybných patchů z tisíce a pár zcela výjimečných Ubunťáků
No nic. Holt je jim přáno, já jdu radši zase na ty patche pro openSUSE
15.7.2008 15:38
freshmouse | skóre: 42
| blog: Bruno Banány
snaží veškerou práci na distribuci ze všech sil schovávat pro sebeByl bych rád, kdybys ocitovala, co ti na mém komentáři vadilo...
a čas a prostředky ušetřené odváděním nekvalitní práce pak mohou věnovat propagaciMáš to podložené čísly, nebo to je další "urban legend"?
a to i na úkor ostatních distribucíOpět bych chtěl citaci...
Ale těch "oprav" jsem už pěkných pár viděla... přečti si třeba tohle, eject je dost jednoduchý na to, aby bylo rychle naprosto jasné, proč je to beznadějně špatně, nic to nespravuje a navíc to něco rozbíjí
Je jasné, že tahle oprava dala autorovi mnohem méně práce než mně napsat patch, který to v openSUSE spravuje doopravdy (upstream je bohužel mrtvý, takže se to asi jinam nikdy nedostane). Jestli zrovna ušetřený čas věnoval jiné práci pro Ubuntu nebo ne je samozřejmě otázka, to, že Ubuntu dává daleko víc člověkohodin do propagace než do vývoje je ale celkem jisté. A pokud jde o pochybné metody propagace, stačí trochu koukat kolem sebe, na to vážně nepotřebuješ shánět někoho ze sociálních věd, aby o tom napsal bakalářku  Ale o tom to vůbec nemělo být Nechť si Ubunťáci třeba chodí po hlavě a odrážejí se ušima, mně se jen nelíbí rytí do cizího článku mimořádně nepěkným způsobem. Marek určitě dělal, co uměl, prostě jen psal o distribuci, kterou používá, a Ty na něj se žvásty o PR... Marek se snaží ostatní něco naučit, a Ty mu v podstatě podsouváš něco ve stylu "stejně to celé napsal jenom proto, aby se tu psalo o openSUSE," což prostě není fér. Nechápu to o to spíš, že v článku je spousta věcí, které si kritiku zaslouží doopravdy a Marek by se z ní mohl jedině poučit.
Byl bych rád, kdybys ocitovala, co ti na mém komentáři vadilo...
Tak ještě jednou:
Pak mě ještě zarazil odkaz na MS a PR OpenSUSE.
O openSUSE viz výše. To, že odkaz na microsoftí stránky má v tomhle článku dobré opodstatnění, je vidět natolik, že první část toho komentáře nejde hodnotit jinak než jako pokus o poněkud nepovedené uplivnutí na cizí práci.
Pokud pořád není jasné proč mi komentář přišel k Markovi nefér, tak už toho asi nechme, nepochopili bychom se
"plive na cizi praci"
Kdybys nepřekrucoval, co říkám... to o plivání jsem myslím dostatečně jasne uvedla jako komentář k té poznámce o Microsoftu, která je tak nesmyslná, že tam fakt nevidím jiné vysvětlení.
Ale o tom to vůbec nemělo být Nechť si Ubunťáci třeba chodí po hlavě a odrážejí se ušima, mně se jen nelíbí rytí do cizího článku mimořádně nepěkným způsobem. Marek určitě dělal, co uměl, prostě jen psal o distribuci, kterou používá, a Ty na něj se žvásty o PR... Marek se snaží ostatní něco naučit, a Ty mu v podstatě podsouváš něco ve stylu "stejně to celé napsal jenom proto, aby se tu psalo o openSUSE," což prostě není fér. Nechápu to o to spíš, že v článku je spousta věcí, které si kritiku zaslouží doopravdy a Marek by se z ní mohl jedině poučit.
Byl bych rád, kdybys ocitovala, co ti na mém komentáři vadilo...
Tak ještě jednou:
Pak mě ještě zarazil odkaz na MS a PR OpenSUSE.
O openSUSE viz výše. To, že odkaz na microsoftí stránky má v tomhle článku dobré opodstatnění, je vidět natolik, že první část toho komentáře nejde hodnotit jinak než jako pokus o poněkud nepovedené uplivnutí na cizí práci.
Pokud pořád není jasné proč mi komentář přišel k Markovi nefér, tak už toho asi nechme, nepochopili bychom se
"plive na cizi praci"
Kdybys nepřekrucoval, co říkám... to o plivání jsem myslím dostatečně jasne uvedla jako komentář k té poznámce o Microsoftu, která je tak nesmyslná, že tam fakt nevidím jiné vysvětlení.
pocit PR clanku Kdyby byl tohle PR článek, tak by si jeho autor zasloužil zápornou výplatuSuhlas. Kazdopadne ten clanok tak posobi, aj ked je asi kazdemu jasne, ze to tak myslene nebolo.
Kdybys nepřekrucoval, co říkám... to o plivání jsem myslím dostatečně jasne uvedla jako komentář k té poznámce o MicrosoftuNo vidis, ja som to nepochopil, ze sa to tyka M$. Kazdopadne ten odkaz ma pre prekladatelov hodnotu. Niekto s tym ma mozno vnutorny problem, ale 98% uzivatelov desktopovych pocitacov je na istu terminologiu zvyknuta a obvykle to nie je typ ludi, ktorych by iny nazov tlacitka alebo polozky menu nerozhodil. Takze informacia, ako je to prelozene v prostredi M$ je uzitocna.
18.7.2008 00:52
freshmouse | skóre: 42
| blog: Bruno Banány
A co se týče odkazu na MS, to snad ani není vtip, to snad muselo být v rámci nějaké choroby, či co... Můžu vědět, jak a komu ze čtenářů ABC Linuxu se hodí překladatelský slovník MS?
Komukoli, kdo se zajímá o lokalizaci softwaru? Mysli si co chceš, ale i když tu firmu asi spousta z nás nemá ráda, přeci jen to vzali docela zgruntu a roky řešili ve spolupráci s UJČ jazykové problémy, na které při lokalizaci naráželi, a následně spoustu těch pravidel poměrně tvrdě vynucovali (tedy, asi tak do roku 2005 ). Takže se to dá brát jako docela relevantní korpus textu.
Reknu to natvdo, lepší není, tečka, finito. (I když samozřejmě každý korpus je třeba brát kriticky, obzvláště v případě třiceti tisíc stránek textu, jako mají MSí databáze, nějaké ty chyby a sporná místa jsou asi všude.) A nepokoušej se argumentovat lokalizací Ubuntu, to by byl vtip horší než špatný - ani já se proti tomu neopovážím postavit současnou lokalizaci třeba openSUSE, je na tom ještě příliš mnoho práce, než aby se to dostalo do podobného stavu. Zatím ještě nikdo jiný než MS nenalil tolik peněz do "jazykových prací" a jejich QA a výsledek tomu odpovídá (leckdy mnohem víc, než v případě samotného SW). Jestli by to nešlo nákladově efektivněji, než taháním peněz z uživatelů , o tom by se asi dalo diskutovat, ale nás to naštěstí nic nestojí, protože to webové rozhraní nikomu nenastavuje kasičku.
A přestože dodavatelů softwaru je spousta, operačních systémů je spousta a aplikací je spousta, před kompilátorem Cčka a anglickou a českou gramatikou a stylistikou jsme si všichni tak nějak rovni. Nebo snad navrhuješ, aby se udělala speciální linuxová čeština, odlišná od microsoftí češtiny a jablíčkové češtiny a suní češtiny (a já nevím kolik češtin ještě může existovat)? (Byl by hřích toho nevyužít, a troufnu si říct, že by to dokonce byla nafoukanost, paličatost a dost možná to snad muselo být v rámci nějaké choroby, či co. )
18.7.2008 08:24
freshmouse | skóre: 42
| blog: Bruno Banány
) již zajeté standardy. Nevím, proč by se např. gnomáci měli vzdávat slov jako karta nebo budiž. A nejen jich.
Problém překladatelů open source SW je spíš ten, že mnozí z nich nemají cit pro češtinu. A taky tomu bezesporu nevěnují tolik času, co v MS, jelikož mimo překládání musejí chodit do školy nebo do práce -- narozdíl od lidí z MS. Ale díky bohu za všechny lidi, co překládají. Nicméně nějaký překladový slovník FrontPage nás opravdu nespasí...
O tom, co MS dokázal s češtinou (ale i angličtinou), bych se ale dost přel, protože co si moje paměť vzpomíná, na Windows byly výhradně rovné (ASCII) uvozovky, spojovníky namísto pomlček atd. A ani po stránce gramatiky to nebylo tak zářné. Spíš bych jako vzor překladatelské jednotnosti viděl OS X, který si vyhrál i s typografií atd. (ale třeba se mýlím, znám jej jen ze snímků obrazovek) -- v české verzi snad ani není, ale ta anglická vypadá dost dobře.
Když se mrkneš třeba na můj překlad Liferea (tímto neříkám, že jsem nějak extra dobrý, je to jen příklad), tak si troufám říci, že je to srovnatelné s jakýmkoli překladem od MS. A to jsem to dělal zadarmo a po nocích. A bez microsoftího slovníku.
Mimochodem, zrovna před třemi nebo čtyřmi dny jsem (nezávisle na článku a diskuzi) začal vytvářet jakýsi překladový slovník pro GNOME. Bude dostupný na GČ, které bude dostupné tak za týden (snad).
P.S.: Někde jsem slyšel, že se živíš překládáním. Otázka na tělo: není to pro MS?
Vždyť tam jsou (neříkám, že se vždy dodržují"Budiž" nikomu brát nebudu, najdou se i horší věci. Ale není dobré být ve všem jiný za každou cenu. Jaký smysl má mít několik kompletních softwarových balíků (OS + grafické prostředí + aplikace) s tím, že každý bude všemu říkat úplně jinak? Jak na to chceš nalákat průměrného (potenciálního) uživatele? Ne že by pro tolik lidí byl tak důležitý faktor (to asi ne), ale nějaká jednotnost by byla k dobru. Tím spíš, že pokud někdo chce používat český systém postavený na Linuxu, tak asi už používal jiný český systém a možná očekává, že většinu věcí podle názvu pozná. OK a Budiž, to máš skoro jako minerálku a sodovku, ale s přidáváním dalších rozdílů bych opatrný.
Nicméně nějaký překladový slovník FrontPage nás opravdu nespasí...Ten nás samozřejmě nespasí. Ale ty další desetitisíce stránek textu by něco zajímavého obsahovat mohly.
 Je trošku škoda, že ta online aplikace je na vyhledávání trošku tupá. To jsem zjistil bohužel až teď. V offline verzi se dají dobře vyhledávat větné konstrukce, takže pokud na nějakou svízelnější narazím a cítím se v tu chvíli trošku tupější než jindy, přijde mi to obvykle vhod, ale tyhle věci já šířit nemůžu. Jen jsem myslel, že i ta online verze bude použitelná i pro tenhle účel, nejen pro přesné termíny, ale asi to tak slavné nebude. Škoda.
Je trošku škoda, že ta online aplikace je na vyhledávání trošku tupá. To jsem zjistil bohužel až teď. V offline verzi se dají dobře vyhledávat větné konstrukce, takže pokud na nějakou svízelnější narazím a cítím se v tu chvíli trošku tupější než jindy, přijde mi to obvykle vhod, ale tyhle věci já šířit nemůžu. Jen jsem myslel, že i ta online verze bude použitelná i pro tenhle účel, nejen pro přesné termíny, ale asi to tak slavné nebude. Škoda.
O tom, co MS dokázal s češtinou (ale i angličtinou), bych se ale dost přel, protože co si moje paměť vzpomíná, na Windows byly výhradně rovné (ASCII) uvozovky, spojovníky namísto pomlček atd. A ani po stránce gramatiky to nebylo tak zářné.O tom nic nevím. Používání pomlček se v českém lokalizovaném textu obecně nedoporučuje, a pokud jsou opravdu nezbytné, jsou povinné správné české uvozovky, a to téměř odjakživa. Ke gramatice a češtině viz konec odpovědi.
Český SW od Maca jsem neviděl, ale jestli je stejně kvalitní, jako applí "cool a in" "české" stránky, tak bych se jím moc nechlubil. Ty mají úroveň snad jako průměrný OSS projekt. Už jen překlepů jsem našel čtyři za dvě minuty, a to ponechávám stranou viditelné šmouhy angličtiny v údajně "českém" textu.
Když se mrkneš třeba na můj překlad Liferea (tímto neříkám, že jsem nějak extra dobrý, je to jen příklad), tak si troufám říci, že je to srovnatelné s jakýmkoli překladem od MS. A to jsem to dělal zadarmo a po nocích. A bez microsoftího slovníku.Ve volném čase (jestli bude :/) se na to kouknu a zkritizuju.
Já dělám susí lokalizaci taky zadarmo a po nocích. Jen teď budu ještě tak měsíc nebo dva vytížený na 130 %, takže vydrž(te).
P.S.: Někde jsem slyšel, že se živíš překládáním. Otázka na tělo: není to pro MS?Asi šest let, ale nejen pro MS - to bylo jen pár drobečků, něco málo do Visty a tak.
Připočti si tam i HW a SW od Cisca, SAPu, IBM (včetně "terminologického dozoru" a korektur po týmu asi čtyř lidí), Novellu a dalších. Takže hovořím ze zkušenosti. Můžu říct, že ze všech textů, co mi kdy přišly pod ruku, vykazují MSí překlady suverénně nejvyšší úroveň konzistence, korektnosti a stylu. Jistě, čas od času narazím na opravdu "roztomilé" lapsy, ale v porovnání s jinými věcmi je to pořád ještě obdivuhodné dílo (třeba SAP? To je jedno velké "Uáááá!" už v angličtině... ). Pokud nejsi schopen uvést nějaký příklad "nezářné gramatiky", tak nemůžu sloužit. (Všiml jsem si, že třeba překlady Axapty jsou trošku (dost) mimo zbytek databáze, ale to je možná tím, že ten software převzali v akvizici. Takové to základní jádro MSího softwaru, tj. Windows a Office, je na tom - až na občas přehnanou formálnost - velice dobře. Sem tam nějaký QAkující byrokrat vymyslel opravdovou obskurnost, ale jestli na každých dvacet slov v QA procesu vylepšených připadá jeden byrokratismus, pořád ještě to znamená, že lokalizační QA má smysl.)
18.7.2008 09:46
freshmouse | skóre: 42
| blog: Bruno Banány
(A je to i případ Liferea. Nicméně o tom si hodlám s Larsem promluvit. Teď jsem mu poslal seznam asi dvaceti myšlenek, takže je na moje komentáře zvyklý. ) O nějaké typografii se nemá ani cenu bavit.
Mimochodem, kolega má teď snad od IBM nějaké vývojové prostředí (založené na Eclipse). "Profesionální překlad" nás velmi baví. Bylo tam např. "No default proposals" (?) a přeložili to jako "Ne výchozí nabídky" (měla to být asi hláška, že to nenalezlo žádnou metodu, kterou by to doplnilo za objekt)... Takže tak.
Uvažujeme-li pod pojmem "Windows" MS Windows + různé aplikace různých dodavatelů, které uživatelé běžní používají, docházíme k závěru, že Windows (tak, jak jsme je definovali) nejsou jednotné ani omylem. A to jak v lokalizaci, tak i třeba v uživatelském rozhraní.Windows samy o sobě a další software od MS jsou přinejmenším v lokalizaci jednotné poměrně hodně. Samozřejmě se to průběžně vyvíjí a před deseti lety celý slovník a doporučená spojení vypadala mírně jinak, ale to se dá čekat. Pokud jde o aplikace jiných dodavatelů, je to jejich blbost, protože glosáře byly prakticky od začátku dostupné, stylové příručky taky, takže nebylo třeba znovuvynalézat kolo. Nejde ani tak o to, že by tyhl materiály slibovaly, že s nimi vytvoříš literární zázrak, ale je to slušný standard, kterého když se jako autor aplikací pro Windows budeš držet, tak se téměř bezpracně dostaneš s kvalitou docela daleko, a lidé pak nebudou muset hledat stejnou věc v různých programech pod jinými názvy. Že v české verzi můžou obě prostředí (okýnka i tučňák) vypadat jako dort pejska a kočičky, za to je tedy třeba poděkovat celému kolektivu individualistických autorů.
Mimochodem, kolega má teď snad od IBM nějaké vývojové prostředí (založené na Eclipse). "Profesionální překlad" nás velmi baví. Bylo tam např. "No default proposals" (?) a přeložili to jako "Ne výchozí nabídky" (měla to být asi hláška, že to nenalezlo žádnou metodu, kterou by to doplnilo za objekt)... Takže tak.No to já nevím, s tím já nemám nic společného.
Kdo vůbec dělá lokalizaci Eclipse? Není to komunitní záležitost? A nechtěj vědět, jak vypadaly i interní texty, co jsem od Velké Modré dostal v někdy roce 2003 s tím, že s nimi mám něco provést. Takže tohle mě tak nějak nepřekvapuje. Nicméně IBM na tom životně nevisí, což není případ MS, proto je na tom MS zákonitě s lokalizací líp, jinak by mimo Spojené státy pohořel. Když budeš prodávat špatně zlokalizovaný databázový server, admini si ho přepnou do angličtiny. Když budeš prodávat špatně zlokalizovaný kancelářský balík, budeš mít mnohem větší problémy to vysvětlit zákazníkům (a sekretářkám ).
 19.7.2008 08:49
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
19.7.2008 08:49
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
Hmm, někdo mi tu někdy řekl, že se můj článek hodí spíš do blogu. Dodnes nevím, co tam vadilo... Každopádně jsem tam neměl nic jako:Uražená ješitnost?
19.7.2008 12:17
freshmouse | skóre: 42
| blog: Bruno Banány
19.7.2008 13:50
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
.Že by bylo potřeba založit ACC (Abc Community Council) ?
19.7.2008 14:18
freshmouse | skóre: 42
| blog: Bruno Banány
 16.7.2008 18:59
Darth Phantom | skóre: 18
| blog: Kelvin_Fitnick
| Doma
. Taky bych ocenil místo zmínek o Suse jiné informace, ale budiž to Markovi přáno...
16.7.2008 18:59
Darth Phantom | skóre: 18
| blog: Kelvin_Fitnick
| Doma
. Taky bych ocenil místo zmínek o Suse jiné informace, ale budiž to Markovi přáno...
Chcete-li z nějakého důvodu udržet překlady konzistentníNení existence jednotné češtiny dostatečný důvod sám o sobě?
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 15.7.2008 08:28
15.7.2008 08:28