Byla vydána (𝕏) nová major verze 17 softwarového nástroje s webovým rozhraním umožňujícího spolupráci na zdrojových kódech GitLab (Wikipedie). Představení nových vlastností i s náhledy a videi v oficiálním oznámení.
Sovereign Tech Fund, tj. program financování otevřeného softwaru německým ministerstvem hospodářství a ochrany klimatu, podpoří vývoj FFmpeg částkou 157 580 eur. V listopadu loňského roku podpořil GNOME částkou 1 milion eur.
24. září 2024 budou zveřejněny zdrojové kódy přehrávače Winamp.
Google Chrome 125 byl prohlášen za stabilní. Nejnovější stabilní verze 125.0.6422.60 přináší řadu oprav a vylepšení (YouTube). Podrobný přehled v poznámkách k vydání. Opraveno bylo 9 bezpečnostních chyb. Vylepšeny byly také nástroje pro vývojáře.
Textový editor Neovim byl vydán ve verzi 0.10 (𝕏). Přehled novinek v příspěvku na blogu a v poznámkách k vydání.
Byla vydána nová verze 6.3 živé linuxové distribuce Tails (The Amnesic Incognito Live System), jež klade důraz na ochranu soukromí uživatelů a anonymitu. Přehled změn v příslušném seznamu. Tor Browser byl povýšen na verzi 13.0.15.
Dnes ve 12:00 byla spuštěna první aukce domén .CZ. Zatím největší zájem je o dro.cz, kachnicka.cz, octavie.cz, uvycepu.cz a vnady.cz [𝕏].
JackTrip byl vydán ve verzi 2.3.0. Jedná se o multiplatformní open source software umožňující hudebníkům z různých částí světa společné hraní. JackTrip lze instalovat také z Flathubu.
Patnáctý ročník ne-konference jOpenSpace se koná 4. – 6. října 2024 v Hotelu Antoň v Telči. Pro účast je potřeba vyplnit registrační formulář. Ne-konference neznamená, že se organizátorům nechce připravovat program, ale naopak dává prostor všem pozvaným, aby si program sami složili z toho nejzajímavějšího, čím se v poslední době zabývají nebo co je oslovilo. Obsah, který vytváří všichni účastníci, se skládá z desetiminutových
… více »Program pro generování 3D lidských postav MakeHuman (Wikipedie, GitHub) byl vydán ve verzi 1.3.0. Hlavní novinkou je výběr tvaru těla (body shapes).
Box je v TeXu řádek, sloupec, tabulka, položka tabulky nebo třeba celá
stránka. Je to pomyslný obdélník ohraničující sazbu. Má svou výšku nad účařím,
hloubku pod účařím a šířku. TeX pracuje jen s těmito rozměrovými údaji,
samotnou kresbu jednotlivých znaků nijak v algoritmech sazby neinterpretuje.
Písmeno můžeme považovat za elementární box. Box se může skládat z boxů
(například řádek, stránka). Obsah složeného boxu je sestaven ze sazby kladené vedle
sebe na společné účaří (\hbox) nebo pod sebe na levou zarážku
(\vbox). Složené boxy se mohou skládat z boxů, které jsou zase
složené boxy. Úroveň vnoření není významně omezena.

Rozměr boxu je odvozen od velikosti sazby, kterou obsahuje. Je to zhruba řečeno nejmenší obdélník obklopující sazbu. Sazba z boxu může ovšem výjimečně přečnívat. Buď proto, že sazba obsahuje zápornou mezeru nebo se jedná o písmeno mírně přesahující hranici svého boxu kvůli kompenzaci optického klamu resp. kvůli speciálnímu tvaru písmene (kurzivní písmena mohou přečnívat přes svůj pravoúhlý box vpravo nahoře a někdy též pod účařím vlevo dole).
Slova se skládají z písmen, tedy z elementárních boxů kladených těsně za sebou zleva doprava. TeX pracuje taky s tabulkou kerningových párů přečtenou z metriky fontu. Podle ní mezi jisté dvojice znaků uvnitř slov klade automaticky mezeru (obvykle zápornou) označovanou v tomto případě jako „kern“. Tabulku kerningových párů navrhuje autor fontu tak, aby vylepšil optické vyrovnání za sebou kladených písmen podle jejich tvaru.
Mezi slovy jsou vloženy pružné mezislovní mezery, jejichž parametry pro základní velikost, toleranci stlačení a roztažení jsou také přečteny z metriky použitého fontu. Tyto mezery jsou označovány jako „glue“, protože mohou být pružné. Svou pružnost uplatní, požaduje-li algoritmus sazby umístění řádku nebo jeho části do pevně stanovené šířky, například při sazbě odstavce do bloku.
Při sazbě sloupce vkládá TeX mezi řádky automaticky další vertikální mezery
typu glue tak, aby pokud možno vzdálenost mezi jednotlivými účařími řádků
byla stále stejná. Přitom požadavek pokud možno lze přesně řídit
nastavením hodnot registrů \baselineskip, \lineskip
a \lineskiplimit. Meziřádkové mezery mají tedy rozdílnou velikost tak,
že kompenzují rozdílné výšky a hloubky jednotlivých řádků.
Nad každou meziřádkovou mezeru ve sloupci vkládá TeX neviditelnou značku nesoucí
celé číslo. Tuto značku označujeme jako „penalty“, protože označuje velikost trestu
za to, že algoritmus rozdělí v následující mezeře sloupec sazby do více
sloupců či do stránek. Pod prvním řádkem odstavce je vložena penalta podle
registru \clubpenalty, pod předposledním řádkem odstavce podle
registru \widowpenalty a mezi ostatními řádky dle registru
\interlinepenalty. Algoritmus má tendenci vybírat místo pro zlom sloupce
tak, aby byl vyhodnocen nejmenší trest. Přitom započítá i další trest, který je
kubicky úměrný velikosti stlačení nebo roztažení mezer typu glue, ke kterému je
nutno přistoupit, aby měl sloupec stanovenou výšku. Sledujeme-li postupně sloupec
sazby, kde jednotlivé řádky jsou boxy, pak se sloupec typicky skládá postupně
z box-penalty-glue, box-penalty-glue atd.
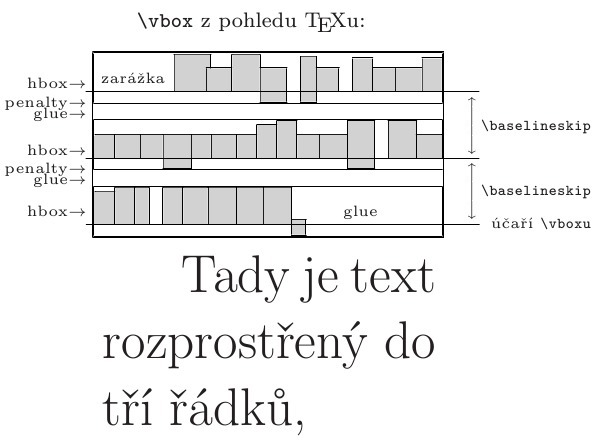
Makra například pro tvorbu nadpisů mohou do sloupce sazby vkládat další boxy a explicitně zadané penalty a glue.
Při sazbě řádku se před mezislovní mezery obvykle žádná penalta nevkládá. Pokud ano, vloží ji tam makro, které tím označuje míru trestu za zlomení řádku v následující mezeře při sestavení odstavce. Takže v řádku se zcela pravidelné střídání box-penalty-glue nevyskytuje, ovšem algoritmus lámání řádků pracuje s penaltami a glue analogicky. Započítává také trest kubicky úměrný míře stlačení nebo roztažení mezer každého řádku při požadavku vyrovnání odstavce do bloku na danou šířku. Tento trest vyjadřující ošklivost řádku se označuje termínem „badness“.
Penalty se pohybují mezi hodnotami −10000 až 10000, přitom záporné hodnoty značí naopak bonus za zlomení v následující mezeře nebo přímo v penaltě, když mezera nenásleduje. Krajní hodnoty tohoto rozsahu mají speciální význam: vynucený zlom a zakázaný zlom.
Zlom je dovolen jen v mezeře typu glue nebo v penaltě. Zlom způsobí, že výsledná sazba už tuto mezeru nebo penaltu (i všechny těsně následující) neobsahuje. Znamená to, že při řádkovém nebo stránkovém zlomu se nenávratně ztrácí původní informace o sazbě (například o tom, jak velká byla mezera v místě zlomu). Z výsledku algoritmu sazby tedy nelze zpětně zrekonstruovat jeho vstup.
Na začátku zpracování TeX otevře k plnění hlavní zabudovaný \vbox,
který je připraven pro pozdější stránkový zlom. V rámci tohoto tzv.
„vertikálního módu“ ovšem TeX typicky narazí na potřebu vytvořit odstavec. To pozná
obvykle dle prvního písmene, které se má vysázet, nebo explicitně pomocí zahajovací
horizontální mezery (\hskip, \indent, \noindent).
V takovém okamžiku TeX alokuje vestavěný \hbox, do kterého vloží
nejprve odstavcovou zarážku a dále tam začne ukládat sazbu odstavce, což činí
v „horizontálním módu“. Uvedený \hbox nakonec obsahuje sazbu celého
odstavce v jediném řádku. Konec odstavce pozná TeX pomocí prázdného řádku ve
zdrojovém souboru, resp. pomocí \par nebo pomocí příkazu pro vložení
vertikální mezery \vskip. Na konci odstavce TeX typicky připojí glue
neomezené pružnosti (mezera ve východovém řádku) a spustí algoritmus zlomu
odstavce do řádků na požadovanou šířku \hsize. Pak se vrátí zpět do
vertikálního módu nadřazeného \vboxu a výsledné řádky odstavce
(\hboxy) do tohoto \vboxu vloží. Poté obvykle při dalším čtení
zdrojového souboru najde znovu důvod k zahájení dalšího odstavce (tím důvodem
je typicky první písmeno dalšího odstavce), odstavec následně v místě prázdného
řádku ukončí, rozlomí jej do řádků, zařadí do \vboxu, pak další odstavec
atd.
Průběžně při plnění hlavního vertikálního boxu je kontrolováno jeho přeplnění dle
požadované výšky strany \vsize. Dojde-li k přeplnění, je nalezeno
optimální místo zlomu. Odlomená část sloupce do výšky \vsize je
distribuována jako \vbox do tzv. \output rutiny, kde lze
pomocí maker TeXu říci, jaké boxy se k tomu mají doplnit (například záhlaví,
zápatí) a vznikne kompletní box, který tvoří jednu stranu dokumentu. Přitom
zbytek sazby (po odlomení) v hlavním vertikálním boxu zůstává a postupně
jsou k němu přidávány další řádky dalších odstavců. Znovu se průběžně
kontroluje přeplnění dle požadované výšky strany a případně vznikají stejným
způsobem další strany dokumentu.
Na konci zpracování odstavce, když je interní \hbox zaplněn sazbou
celého odstavce, hledá TeX optimální místa zlomu pro porcování do řádků
se stanovenou šířkou \hsize. Projde přitom teoreticky všechna
možná řešení, která nepřesáhnou stanovenou toleranci pro „badness“ všech
výsledných řádků a vybere mezi těmito řešeními takové, které má nejmenší
součet kvadrátů všech penalt za zlomy, za rozdělení slov a za „badness“
jednotlivých řádků (tzv. cena zlomu). Do vzorce zahrne ještě další parametry
[TBN sekce 6.4].
V tomto svém globálním pohledu na odstavec při řádkovém zlomu předběhl TeX výrazně dobu svého vzniku a ještě dnes se k této metě kvality řádkového zlomu ostatní software zpracovávající sazbu blíží jen pozvolně. Tupý algoritmus, který odlupuje řádky postupně už během čtení odstavce, není v TeXu použit. Že to má význam, se můžeme přesvědčit v této ukázce, ve které vidíme srovnání výsledku odstavcového zlomu stejného textu, jednou ve Wordu, podruhé v InDesignu a potřetí v TeXu. Že je ten třetí sloupeček ukázky označen jako LaTeX a nikoli TeX, toho si prosím nevšímejte. LaTeXoví uživatelé často nedokáží rozlišit, co je dílem makra LaTeXu a za co vděčí TeXu samotnému.
Hledání optimálního řádkového zlomu odstavce je řízeno mnoha parametry a je
tříprůchodové. V prvním průchodu se TeX pokusí najít řešení bez dělení slov.
Když se to nepodaří, vyznačí si v odstavci všechna místa dělení slov
a zkusí to znovu i s možným dělením slov. Za každé rozdělené slovo
si připočítá stanovenou penaltu a za každé dva po sobě jdoucí řádky
s rozděleným slovem přihodí další položku do celkové ceny zlomu pro dané
řešení. A zase hledá řešení s nejmenší cenou zlomu. Když se to za stanovené
tolerance nepovede, pustí se do třetího průchodu, který proběhne stejně jako druhý,
jen je zde povoleno roztáhnout mezery víc, než je obvyklé. V takovém případě
typicky uvidíme na terminálu varování Underfull \hbox badness.... Pokud ani
po třetím průchodu není dosaženo řešení se stanovenou tolerancí, dočkáme se chyby
Overfull \hbox.
Algoritmus pro vyhledání míst pro dělení slov v TeXu je výsledkem
dizertační práce Franklina Lianga, který byl
v době vzniku TeXu Knuthovým Ph.D. studentem. Pointa tohoto algoritmu je
v tom, že je k dispozici externí program patgen, který
čte obsáhlé slovníky pro daný jazyk s vy-zna-če-ný-mi vzory dělení
slov a informace komprimuje do „vzoru dělení slov“ v rozsahu pár
desítek kilobytů. Tento vzor je pak načítán TeXem v parametru příkazu
\patterns během generování formátu a TeX je z toho schopen
rekonstruovat původní místa dělení slov. Vzory dělení slov pro desítky jazyků jsou
volně k dispozici v TeXové distribuci. Ovšem ty slovníky, ze kterých to
bylo generováno, typicky přístupné nejsou. Liangův algoritmus později převzaly
všechny programy na zpracování textu od Wordu přes LibreOffice až po InDesign.
Sazeč může dát pokyn nějaký odstavec přesadit tak, aby byl třeba o řádek
delší nebo kratší, než odpovídá optimálnímu řešení (příkazem \looseness).
Takové dodatečné vkládání \looseness pro některé odstavce je
nutná manuální práce sazeče, který třeba pomocí penalt zakáže odlomit první
i poslední řádek odstavce od zbytku, a přitom by chtěl mít na každé
stránce stejný počet řádků. Automatické hledání společného optima řádkového
i stránkového zlomu zatím neexistuje.
Povšimněte si, že kapitola začínající pravidelně na nové stránce je vertikální analogie odstavce. Podléhá vertikálnímu zlomu do stránek, přitom poslední stránka kapitoly má obvykle za posledním řádkem bílé místo (východová stránka). Mohli bychom tedy analogicky použít globální algoritmus pro lámání kapitoly do stránek jako do řádků odstavce. Algoritmy zlomu do stran a zlomu odstavců by mohly nějak komunikovat mezi sebou a společně hledat jakési globální optimální řešení. K implementaci této myšlenky Knuth nepřistoupil pro výpočetní náročnost. V době vzniku TeXu navíc nebylo myslitelné, aby se celý dokument vešel do operační paměti počítače. Dnes jsou technické možnosti mnohem dále a myslím si, že by stálo za to tuto otázku znovu otevřít.
Závěrečný příklad je takový drobný test pozornosti. Předpokládejme tento zdrojový text:
\chyph % vzory dělení slov pro češtinu, použijte csplain
První odstavec.
\hbox{D}ruhý \hbox{o}dstavec.
\bigskip\hrule\bigskip
Třetí odstavec obsahuje vysvětlení tohoto příkladu:
\input komentar.tex % tento soubor obsahuje spoiler
\hsize=0.5\hsize % šířka sazby bude poloviční
\end % ukončí poslední odstavec, poslední stránku i činnost TeXu
Před tím, než kliknete na výsledek, zkuste si tipnout, jak bude sazba z tohoto příkladu vypadat.
V příštím díle ukážeme práci s boxy z pohledu programátora maker při návrhu vzhledu dokumentu.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
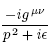 13.2.2014 19:17
egg | skóre: 20
| Praha
13.2.2014 19:17
egg | skóre: 20
| Praha
Čeho si na TeXu opravdu cením, je sazba vzorců a právě zde popsané algoritmy. Ač je TeX automat, provádí sazbu „s rozmyslem“ a výsledek je pěkný, text se dobře čte. Umí například dělit slova na konci řádku, ale když to jde jinak, nedělá to. Mezery mezi slovy i mezi řádky na sebe opticky zbytečně neupozorňují atd. Za to mám TeX rád.
Co mi ale občas dělá potíže, je umisťování obrázků. Typicky píšu nějaký učební text a ilustrační obrázek odskočí na jinou stránku, než kde je k němu výklad. Pokud je více obrázků nedaleko sebe, odskočí někdy dost daleko. Moc si s tím nevím rady, většinou kvůli tomu měním text, aby byl někde delší nebo kratší, případně napíšu vložení obrázku k jinému odstavci, abych ho přibližně dostal, kde si jej představuji. Ale pokud pak do textu zasáhnu z jiných důvodů, zase se to rozbije. Nemám to příliš pod kontrolou.
 13.2.2014 20:42
Stanislav Brabec | skóre: 45
| Praha
14.2.2014 16:05
Stanislav Brabec | skóre: 45
| Praha
13.2.2014 20:42
Stanislav Brabec | skóre: 45
| Praha
14.2.2014 16:05
Stanislav Brabec | skóre: 45
| Praha
def\PAR{%
\ifhmode
\unskip \hskip\parfillskip \vadjust{\vskip\parskip}\break \fi
\indent}
\let\par\PAR
 15.2.2014 07:23
olsak | skóre: 29
15.2.2014 07:23
olsak | skóre: 29
Jestliže má kapitola v knize třicet stran, opravdu málokdo si přeje, aby po editaci na str. 29 počítač nazřel, že lze nalézt lepší zlom strany šestMyslím, že to by se dalo řešit nastavením vhodného parametru tak, aby počítač nenazřel, když sazeč nechce. Pokud naopak chceme dodržet řádkový rejstřík a zakážeme parchanty (sazečkou hantýrkou tím je řečeno, že chceme mít na každé stránce stejný počet řádků a nechceme odlomit první nebo poslední řádek odstavce), možná bychom uvítali, že to nemusíme ošetřovat ručně. Někde jsem slyšel, že důsledné propojení řádkového a stránkového algoritmu by vedlo na algoritmus s exponenciální složitostí (resp. P=NP), což rovněž znamená, že to není implementovatelné v úplné obecnosti. A Knuth se do omezujících podmínek, za kterých by se to implementovat dalo, asi nechtěl pouštět. A taky stránkový rejstřík nejspíš neřešil. Vyvozuji tak z toho, že v plainTeXu je nastaveno plno pružných vertikálních mezer a Knuth dělal především knížky s matematickými vzorečky, kde stránkový rejstřík skutečně není hlavní požadavek. Takže to jsou možná důvody, proč v TeXu zpětné ovlivňování řádkového algoritmu stránkovým nemáme. Moc se o tom neví, ale částečné ovlivnění těch algoritmů, které může způsobit překvapení, je v TeXu přítomno: v hotovém dokumentu přidáte nebo uberete čárku v jediném odstavci, ověříte si, že odstavec má po úpravě stejný počet řádků, ale dokument je třeba o stránku delší. Proč? Protože v modifikovaném odstavci se jinak rozdělí slova a pod řádky s rozdělenými slovy TeX strká \brokenpenalty, což ovlivní stránkový zlom.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz